DTSA 5505 - Ask A Manager Survey Reported Salaries from 2022 and 2023
- 2023 Data From: Ask A Manager 2023 Survey Post
- 2022 Data From: Ask A Manager 2022 Survey Post
Table of Contents
- Project Overview
- Vectorizing Job Title Vector
- Clustering to Proxy Job Title
- Data Exploration and Analysis
- Predicting Salary
- Final Thoughts and Project Next Steps
Project Overview
Project Goals
The overall project goals mainly deal with going through the entire data mining workflow, from data collection to modeling and iterating based on results. The only parts of the data mining workflow that will not be covered is the data warehousing (current warehousing, if applicable, will be in csvs), and initial data collection (surveying).
The project should clearly walk through the data cleaning and combining process, as well as any feature engineering necessary for analysis or modeling. The project should also attempt to utilize supervised and unsupervised machine learning models to enrich the data and analysis.
- Clean Data
- Combine Data
- Explore Data and Trends, Including:
- Is There a Gender Pay Gap?
- Are There Significant Differences in Pay Between Industries, Functional Areas?
- Is There a Trend in Salaries From 2022 - 2023?
- Develop Strategy for Free Response Job Description, Industries, and Functional Areas
- Develop Prediction Algorithm for Salary and Bonus (Total Compensation)
- Develop Classification Algorithm for Job Title (free text response variable)
- Develop Clustering Algorithm and Explore Similarities and Differences Between Cluster Members
Setup
# Packages
## Various
import pickle
import random
## Dates and Times
import pytz
from dateutil import parser
from datetime import timezone,datetime,timedelta
from dateutil.relativedelta import relativedelta
## String manipulation
import string
import re #regex
import json #json parsing
## Data Generation
import random
# Data Manipulation
import pandas as pd
import numpy as np
## Vector Math
from numpy.linalg import norm
## Math
import math
## Statistical Tests
from scipy.stats import ttest_ind
from scipy.stats import ttest_rel
from scipy.stats import median_test
# Data Visualization
import matplotlib as mpl
import matplotlib.pyplot as plt
import plotly as pl
import plotly.express as px
import plotly.graph_objects as go
# Language Processing
import spacy
nlp = spacy.load("en_core_web_md")
# SciKit Learn
from sklearn.cluster import KMeans
from sklearn.cluster import Birch
from sklearn.cluster import OPTICS
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.feature_extraction import FeatureHasher
from sklearn.model_selection import train_test_split
Load and Clean Data
In order to clean the data, the following steps were taken:
- Load Data
- Rename Columns
- Add ‘year’ column for form response year
- Fill and Remove NAs as appropriate
- Clean Column Responses
- From the visible survey results, we know that 2022 had more multiple selection options. For simplicity, we will select the first item. This seems to be the first user selection, not the alphabetical order
- This was corrected in the 2023 survey in some instances; listed categories have been updated in the 2023 survey to keep responses in line
- There is a possibility that a self reported category may be parsed incorrectly if the response used a comma
- In the 2023 survey, education responses could be free response
- Changing Categorical Variables to Ordinal Variables
# Helper Functions
def clean_cat(ind, area, flag):
if flag == 1:
if ind == 'NAN':
if area != 'NAN':
return area
return ind
if flag == 2:
if area == 'NAN':
if ind != 'NAN':
return ind
return area
# 2022 Form Responses
aam_2022 = pd.read_csv('aam_survey_2022.csv')
aam_2022 = aam_2022.rename(columns = {'Timestamp':'form_timestamp', 'How old are you?':'age_group',
'What industry is your employer in?':'industry',
'What is the functional area of your job (this might be different from your companys industry)?':'functional_area',
'Job title':'job_title',
'If your job title needs additional context, please clarify here:':'add_job_context',
'What is your annual salary? This should be your GROSS (pre-tax) income. (Youll indicate the currency in a later question.) If you are part-time or hourly, please enter an annualized equivalent -- what you would earn if you worked the job 40 hours a week, 52 weeks a year.':'gross_salary',
'How much additional monetary compensation do you get, if any (for example, bonuses or overtime in an average year)? Only include monetary compensation here, not the value of benefits, tuition reimbursement, etc. If your bonus or overtime varies from year to year, use the most recent figures.':'bonus',
'Please indicate the currency':'currency',
'If Other, please indicate the currency here: ':'currency_text',
'If your income needs additional context, please provide it here:':'add_salary_context',
'What country do you work in? (Countries listed had by far the largest representation last year. Please write in your country if its not listed.)':'country',
'If youre in the U.S., what state do you work in?':'us_state',
'What city do you work in?':'city', 'Are you remote or on-site?':'work_type',
'How many years of professional work experience do you have overall?':'exp_group',
'How many years of professional work experience do you have in your field?':'exp_field_group',
'What is your highest level of education completed?':'education',
'What is your gender?':'gender', 'What is your race? (Choose all that apply.)':'race'})
# 2023 Form Responses
aam_2023 = pd.read_csv('aam_survey_2023.csv')
aam_2023 = aam_2023.rename(columns = {'Timestamp':'form_timestamp', 'How old are you?':'age_group',
'Industry':'industry', 'Functional area of job':'functional_area',
'Job title':'job_title', 'Job title - additional context':'add_job_context', 'Annual salary (gross)':'gross_salary',
'Additional monetary compensation':'bonus', 'Currency':'currency', 'Currency - other':'currency_text',
'Income - additional context':'add_salary_context', 'Country':'country', 'State':'us_state', 'City':'city',
'Remote or on-site?':'work_type', 'Years of experience, overall':'exp_group',
'Years of experience in field':'exp_field_group', 'Highest level of education completed':'education',
'Gender':'gender', 'Race':'race'})
aam_2022['year'] = 2022
aam_2023['year'] = 2023
# Fill NAs for Categorical Variables
aam_2022[['country','us_state','city','work_type','gender','race']] = aam_2022[['country','us_state','city','work_type','gender','race']].fillna(value='Unknown')
aam_2023[['country','us_state','city','work_type','gender','race']] = aam_2023[['country','us_state','city','work_type','gender','race']].fillna(value='Unknown')
# Clean Categories
aam_2022['race'] = aam_2022['race'].apply(lambda x: str(x).replace('Hispanic, Latino, or Spanish origin', 'Hispanic or Latino or Spanish origin'))
aam_2023['race'] = aam_2023['race'].apply(lambda x: str(x).replace('Hispanic, Latino, or Spanish origin', 'Hispanic or Latino or Spanish origin'))
aam_2022['race'] = aam_2022['race'].apply(lambda x: str(x).replace('Another option not listed here or prefer not to answer', 'Unknown'))
aam_2023['race'] = aam_2023['race'].apply(lambda x: str(x).replace('Another option not listed here or prefer not to answer', 'Unknown'))
aam_2022['gender'] = aam_2022['gender'].apply(lambda x: str(x).replace('Other or prefer not to answer', 'Unknown'))
aam_2023['gender'] = aam_2023['gender'].apply(lambda x: str(x).replace('Other or prefer not to answer', 'Unknown'))
aam_2022['gender'] = aam_2022['gender'].apply(lambda x: str(x).split(',')[0])
aam_2023['gender'] = aam_2023['gender'].apply(lambda x: str(x).split(',')[0])
aam_2022['race'] = aam_2022['race'].apply(lambda x: str(x).split(',')[0])
aam_2023['race'] = aam_2023['race'].apply(lambda x: str(x).split(',')[0])
aam_2022['work_type'] = aam_2022['work_type'].apply(lambda x: str(x).replace("Other/it's complicated", 'Other'))
aam_2023['work_type'] = aam_2023['work_type'].apply(lambda x: str(x).replace("Other/it's complicated", 'Other'))
aam_2022['work_type'] = aam_2022['work_type'].apply(lambda x: str(x).replace("Fully remote, Hybrid", 'Other'))
aam_2022['country'] = aam_2022['country'].apply(lambda x: str(x).split(',')[0])
aam_2022['us_state'] = aam_2022['us_state'].apply(lambda x: str(x).split(',')[0])
aam_2022['industry'] = aam_2022['industry'].apply(lambda x: str(x).replace('Accounting, Banking & Finance', 'Accounting & Banking & Finance'))
aam_2022['industry'] = aam_2022['industry'].apply(lambda x: str(x).replace('Leisure, Sport & Tourism', 'Leisure & Sport & Tourism'))
aam_2022['industry'] = aam_2022['industry'].apply(lambda x: str(x).replace('Marketing, Advertising & PR', 'Marketing & Advertising & PR'))
aam_2022['industry'] = aam_2022['industry'].apply(lambda x: str(x).split(',')[0])
aam_2022['functional_area'] = aam_2022['functional_area'].apply(lambda x: str(x).replace('Accounting, Banking & Finance', 'Accounting & Banking & Finance'))
aam_2022['functional_area'] = aam_2022['functional_area'].apply(lambda x: str(x).replace('Leisure, Sport & Tourism', 'Leisure & Sport & Tourism'))
aam_2022['functional_area'] = aam_2022['functional_area'].apply(lambda x: str(x).replace('Marketing, Advertising & PR', 'Marketing & Advertising & PR'))
aam_2022['functional_area'] = aam_2022['functional_area'].apply(lambda x: str(x).split(',')[0])
aam_2023['industry'] = aam_2023['industry'].apply(lambda x: str(x).replace('Accounting, Banking & Finance', 'Accounting & Banking & Finance'))
aam_2023['industry'] = aam_2023['industry'].apply(lambda x: str(x).replace('Leisure, Sport & Tourism', 'Leisure & Sport & Tourism'))
aam_2023['industry'] = aam_2023['industry'].apply(lambda x: str(x).replace('Marketing, Advertising & PR', 'Marketing & Advertising & PR'))
aam_2023['functional_area'] = aam_2023['functional_area'].apply(lambda x: str(x).replace('Accounting, Banking & Finance', 'Accounting & Banking & Finance'))
aam_2023['functional_area'] = aam_2023['functional_area'].apply(lambda x: str(x).replace('Leisure, Sport & Tourism', 'Leisure & Sport & Tourism'))
aam_2023['functional_area'] = aam_2023['functional_area'].apply(lambda x: str(x).replace('Marketing, Advertising & PR', 'Marketing & Advertising & PR'))
# Fill NAs for Numberic Variables
aam_2022['gross_salary'] = aam_2022['gross_salary'].apply(lambda x: str(x).replace(',',''))
aam_2022['bonus'] = aam_2022['bonus'].apply(lambda x: str(x).replace(',',''))
aam_2022 = aam_2022.astype({'gross_salary':'float','bonus':'float'})
aam_2022['bonus'].fillna(value=0, inplace=True)
aam_2023['gross_salary'] = aam_2023['gross_salary'].apply(lambda x: str(x).replace(',',''))
aam_2023['bonus'] = aam_2023['bonus'].apply(lambda x: str(x).replace(',',''))
aam_2023 = aam_2023.astype({'gross_salary':'float','bonus':'float'})
aam_2023['bonus'].fillna(value=0, inplace=True)
# Drop Potentially Bad or Incomplete Data
print('2022 Total Rows:',aam_2022.shape[0])
print('2023 Total Rows:',aam_2023.shape[0])
aam_2022_rows = aam_2022.shape[0]
aam_2023_rows = aam_2023.shape[0]
aam_2022.dropna(subset=['gross_salary','age_group','industry','functional_area','job_title','education'], inplace=True)
aam_2023.dropna(subset=['gross_salary','age_group','industry','functional_area','job_title','education'], inplace=True)
# Additional Cleaning and Filtering for Valid Education Category
edu_lvls = ['High School', 'Some college', 'College degree', "Master's degree", 'PhD', 'Professional degree (MD, JD, etc.)']
aam_2023.loc[aam_2023['education'].str.contains('Associate', case=False), 'education'] = 'Some college'
aam_2023.loc[aam_2023['education'].str.contains('Vocational', case=False), 'education'] = 'Some college'
aam_2023.loc[aam_2023['education'].str.contains('Technical', case=False), 'education'] = 'Some college'
aam_2023.loc[aam_2023['education'].str.contains('Trade', case=False), 'education'] = 'Some college'
aam_2023.loc[aam_2023['education'].str.contains('Bachelor', case=False), 'education'] = 'College degree'
aam_2023.loc[aam_2023['education'].str.contains('B.A ', case=False), 'education'] = 'College degree'
aam_2023.loc[aam_2023['education'].str.contains('B.S ', case=False), 'education'] = 'College degree'
aam_2023.loc[aam_2023['education'].str.contains('BA ', case=False), 'education'] = 'College degree'
aam_2023.loc[aam_2023['education'].str.contains('BS ', case=False), 'education'] = 'College degree'
aam_2023.loc[aam_2023['education'].str.contains('college degree', case=False), 'education'] = 'College degree'
aam_2023.loc[aam_2023['education'].str.contains("Master's Degree", case=False), 'education'] = "Master's degree"
aam_2023.loc[aam_2023['education'].str.contains("MS ", case=False), 'education'] = "Master's degree"
aam_2023.loc[aam_2023['education'].str.contains("EdD ", case=False), 'education'] = 'Professional degree'
aam_2023 = aam_2023[aam_2023['education'].isin(edu_lvls)]
# Formatting string Fields
aam_2022['industry'] = aam_2022['industry'].apply(lambda x: x.upper().rstrip().lstrip())
aam_2022['functional_area'] = aam_2022['functional_area'].apply(lambda x: x.upper().rstrip().lstrip())
aam_2022['job_title'] = aam_2022['job_title'].apply(lambda x: x.upper().rstrip().rstrip().lstrip())
aam_2022['country'] = aam_2022['country'].apply(lambda x: x.upper().rstrip().rstrip().lstrip())
aam_2022['currency'] = aam_2022['currency'].apply(lambda x: x.upper().rstrip().rstrip().lstrip())
aam_2022['city'] = aam_2022['city'].apply(lambda x: x.upper().rstrip().rstrip().lstrip())
aam_2023['industry'] = aam_2023['industry'].apply(lambda x: x.upper().rstrip().lstrip())
aam_2023['functional_area'] = aam_2023['functional_area'].apply(lambda x: x.upper().rstrip().lstrip())
aam_2023['job_title'] = aam_2023['job_title'].apply(lambda x: x.upper().rstrip().lstrip())
aam_2023['country'] = aam_2023['country'].apply(lambda x: x.upper().rstrip().rstrip().lstrip())
aam_2023['currency'] = aam_2023['currency'].apply(lambda x: x.upper().rstrip().rstrip().lstrip())
aam_2022['city'] = aam_2022['city'].apply(lambda x: x.upper().rstrip().rstrip().lstrip())
# Fill in NAN's for industry and functional_area
aam_2022['industry'] = aam_2022.apply(lambda x: clean_cat(x['industry'], x['functional_area'], 1), axis=1)
aam_2022['functional_area'] = aam_2022.apply(lambda x: clean_cat(x['industry'], x['functional_area'], 2), axis=1)
aam_2023['industry'] = aam_2023.apply(lambda x: clean_cat(x['industry'], x['functional_area'], 1), axis=1)
aam_2023['functional_area'] = aam_2023.apply(lambda x: clean_cat(x['industry'], x['functional_area'], 2), axis=1)
aam_2022 = aam_2022[aam_2022['functional_area'] != 'NAN']
aam_2023 = aam_2023[aam_2023['functional_area'] != 'NAN']
aam_2022 = aam_2022[aam_2022['job_title'].str.count('[A-z]')>0]
aam_2023 = aam_2023[aam_2023['job_title'].str.count('[A-z]')>0]
print('2022 Complete Rows:',aam_2022.shape[0])
print('2023 Complete Rows:',aam_2023.shape[0])
print('2022 Row Loss:',aam_2022_rows - aam_2022.shape[0])
print('2023 Row Loss:',aam_2023_rows - aam_2023.shape[0])
# Ordinal-ization of Categories
exp_groups = pd.DataFrame(np.unique(aam_2022['exp_group']), columns = {'group'})
exp_groups['levels'] = [1,5,2,6,7,8,3,4]
aam_2022.loc[aam_2022['age_group'].str.contains('under 18', case=False), 'age_group'] = '18 or under'
aam_2022['age_group_o'] = pd.factorize(aam_2022['age_group'], sort=True)[0]+1
aam_2022 = aam_2022.merge(exp_groups, how='left', left_on='exp_group', right_on='group')
aam_2022 = aam_2022.drop(columns={'group'})
aam_2022 = aam_2022.rename(columns={'levels':'exp_group_o'})
aam_2022 = aam_2022.merge(exp_groups, how='left', left_on='exp_field_group', right_on='group')
aam_2022 = aam_2022.drop(columns={'group'})
aam_2022 = aam_2022.rename(columns={'levels':'exp_field_group_o'})
aam_2023.loc[aam_2023['age_group'].str.contains('under 18', case=False), 'age_group'] = '18 or under'
aam_2023['age_group_o'] = pd.factorize(aam_2023['age_group'], sort=True)[0]+1
aam_2023 = aam_2023.merge(exp_groups, how='left', left_on='exp_group', right_on='group')
aam_2023 = aam_2023.drop(columns={'group'})
aam_2023 = aam_2023.rename(columns={'levels':'exp_group_o'})
aam_2023 = aam_2023.merge(exp_groups, how='left', left_on='exp_field_group', right_on='group')
aam_2023 = aam_2023.drop(columns={'group'})
aam_2023 = aam_2023.rename(columns={'levels':'exp_field_group_o'})
edu_groups = pd.DataFrame(np.unique(aam_2022['education']), columns = {'group'})
edu_groups['levels'] = [3,1,4,6,5,2]
aam_2022 = aam_2022.merge(edu_groups, how='left', left_on='education', right_on='group')
aam_2022 = aam_2022.drop(columns={'group'})
aam_2022 = aam_2022.rename(columns={'levels':'education_o'})
aam_2023 = aam_2023.merge(edu_groups, how='left', left_on='education', right_on='group')
aam_2023 = aam_2023.drop(columns={'group'})
aam_2023 = aam_2023.rename(columns={'levels':'education_o'})
# Adding Additional Columns
aam_2022['total_gross_salary'] = aam_2022['gross_salary'] + aam_2022['bonus']
aam_2023['total_gross_salary'] = aam_2023['gross_salary'] + aam_2023['bonus']
# Combined Data Frame
aam = pd.concat([aam_2022, aam_2023], ignore_index=True)
print('Columns:', len(aam.columns))
2022 Total Rows: 15701
2023 Total Rows: 17016
2022 Complete Rows: 15514
2023 Complete Rows: 16849
2022 Row Loss: 187
2023 Row Loss: 167
Columns: 26
Analysis of Basic Data Attributes
Looking at some of the most basic statistics on the number of unique responses in each category and the overall maximum and minimum of the two numeric responses, there are not many surprises, especially when taking into account that responses can be reported in various currencies.
There may be potential issues with the large amount of Industries and Functional Areas, but as there were listed Industries/Functional Areas, ideally most data will fall into those categories.
# Category Counts
print('Age Groups:',len(np.unique(aam['age_group'])))
print('Industries:',len(np.unique(aam['industry'])))
print('Functional Areas:',len(np.unique(aam['functional_area'])))
print('Job Titles:',len(np.unique(aam['job_title'])))
print('Max Gross Salary:',max(aam['gross_salary']))
print('Minimum Gross Salary:',min(aam['gross_salary']))
print('Max Bonus Compensation:',max(aam['bonus']))
print('Minimum Bonus Compensation:',min(aam['bonus']))
print('Countries:',len(np.unique(aam['country'])))
print('US States:',len(np.unique(aam['us_state'])))
print('Cities:',len(np.unique(aam['city'])))
print('Work Type:',len(np.unique(aam['work_type'])))
print('Experience Groups:',len(np.unique(aam['exp_group'])))
print('Field Experience Groups:',len(np.unique(aam['exp_field_group'])))
print('Education:',len(np.unique(aam['education'])))
print('Genders:',len(np.unique(aam['gender'])))
print('Race:',len(np.unique(aam['race'])))
Age Groups: 7
Industries: 904
Functional Areas: 1341
Job Titles: 14282
Max Gross Salary: 70000000.0
Minimum Gross Salary: 0.0
Max Bonus Compensation: 65500000.0
Minimum Bonus Compensation: 0.0
Countries: 121
US States: 69
Cities: 6472
Work Type: 5
Experience Groups: 8
Field Experience Groups: 8
Education: 6
Genders: 4
Race: 7
Looking more at the Industries and Functional Areas, we can assess the overall distribution of count of responses in terms of unique string responses. From the survey, we know that there are a handful of hard-coded industries and functional areas, but there is additionally a free-text option where respondents can enter their own answer if none apply.
Job Title, on the other hand, is a completely free-text field. We would expect a large amount of the response values to be unique or have fewer than a handful of responses.
# Most Responses Fall Into a Small Subset of All Reported Industries/Functional Areas
unique_industries = aam[['industry','gross_salary']].groupby(['industry'], as_index=False).count().sort_values('gross_salary', ascending=False)
print('Total Industries:', len(unique_industries))
print('Total Counts:', sum(unique_industries['gross_salary']))
print('Industries With Fewer than 10 Responses:', len(unique_industries[unique_industries['gross_salary'] < 10]))
print('Total Counts for Industries With Fewer than 10 Responses:', sum(unique_industries[unique_industries['gross_salary'] < 10]['gross_salary']))
print('Percent of Total:', sum(unique_industries[unique_industries['gross_salary'] < 10]['gross_salary'])/sum(unique_industries['gross_salary'])*100,'%')
print('')
unique_areas = aam[['functional_area','gross_salary']].groupby(['functional_area'], as_index=False).count().sort_values('gross_salary', ascending=False)
print('Total Functional Areas:', len(unique_areas))
print('Total Counts:', sum(unique_areas['gross_salary']))
print('Industries With Fewer than 10 Responses:', len(unique_areas[unique_areas['gross_salary'] < 10]))
print('Total Counts for Industries With Fewer than 10 Responses:', sum(unique_areas[unique_areas['gross_salary'] < 10]['gross_salary']))
print('Percent of Total:', sum(unique_areas[unique_areas['gross_salary'] < 10]['gross_salary'])/sum(unique_areas['gross_salary'])*100,'%')
print('')
unique_jobs = aam[['job_title','gross_salary']].groupby(['job_title'], as_index=False).count().sort_values('gross_salary', ascending=False)
print('Total Job Titles Areas:', len(unique_jobs))
print('Total Counts:', sum(unique_jobs['gross_salary']))
print('Industries With Fewer than 10 Responses:', len(unique_jobs[unique_jobs['gross_salary'] < 10]))
print('Total Counts for Job Titles With Fewer than 10 Responses:', sum(unique_jobs[unique_jobs['gross_salary'] < 10]['gross_salary']))
print('Percent of Total:', sum(unique_jobs[unique_jobs['gross_salary'] < 10]['gross_salary'])/sum(unique_jobs['gross_salary'])*100,'%')
Total Industries: 904
Total Counts: 32363
Industries With Fewer than 10 Responses: 850
Total Counts for Industries With Fewer than 10 Responses: 1177
Percent of Total: 3.6368692642832863 %
Total Functional Areas: 1341
Total Counts: 32363
Industries With Fewer than 10 Responses: 1265
Total Counts for Industries With Fewer than 10 Responses: 1812
Percent of Total: 5.598986496925502 %
Total Job Titles Areas: 14282
Total Counts: 32363
Industries With Fewer than 10 Responses: 13896
Total Counts for Job Titles With Fewer than 10 Responses: 19827
Percent of Total: 61.264406884405034 %
# Removing All Industries and Functional Areas With Less Than 10 Responses
small_industries = np.unique(unique_industries[unique_industries['gross_salary'] < 10]['industry'])
small_areas = np.unique(unique_areas[unique_areas['gross_salary'] < 10]['functional_area'])
aam_2022 = aam_2022[aam_2022['industry'].isin(small_industries) == False]
aam_2023 = aam_2023[aam_2023['industry'].isin(small_industries) == False]
aam = aam[aam['industry'].isin(small_industries) == False]
aam_2022 = aam_2022[aam_2022['functional_area'].isin(small_areas) == False]
aam_2023 = aam_2023[aam_2023['functional_area'].isin(small_areas) == False]
aam = aam[aam['functional_area'].isin(small_areas) == False]
aam_2022 = aam_2022.reset_index(drop=True)
aam_2023 = aam_2023.reset_index(drop=True)
aam = aam.reset_index(drop=True)
print('2022 After Removal of Small Industries/Areas:',aam_2022.shape[0])
print('2023 After Removal of Small Industries/Areas:',aam_2023.shape[0])
print('All Data After Removal of Small Industries/Areas:',aam.shape[0])
print('Industries:',len(np.unique(aam['industry'])))
print('Functional Areas:',len(np.unique(aam['functional_area'])))
2022 After Removal of Small Industries/Areas: 14096
2023 After Removal of Small Industries/Areas: 15618
All Data After Removal of Small Industries/Areas: 29714
Industries: 54
Functional Areas: 76
Vectorizing Job Titles
In the survey, job title is a completely free text field. While this is great for being able to accurately represent a respondence’s job title, this creates issues with grouping and classifying job types. For example, if one response reports their job title as Data Analysis and another respondent reports their job type as Business Analyst, while different jobs, they are functionally very similar; however, grouping just on text will not relate these two job titles.
From the analysis above, job titles with less than 10 responses make up over half of the data. This is problematic if we use job title as a categorical variable, modeling could take a long time due to the number of dummy variables created, or the actual model could be incorrect due to the low amount of responses per job title.
To solve this problem, we can use various methods in Python to create vectors from words and sentences. We can then use various methods to assess similarity. Below is an example using the scapy package to create and compare sentence vectors.
# NLP Example
print(nlp(aam.loc[0,'job_title']).text,":",nlp(aam.loc[0,'job_title']).vector_norm)
print('DATA SCIENTIST:',nlp('DATA SCIENTIST').vector_norm)
print('data scientist:',nlp('data scientist').vector_norm)
print('scientist data:',nlp('scientist data').vector_norm)
print('scientist:',nlp('scientist').vector_norm)
print('DEBT ADVISOR:',nlp('DEBT ADVISOR').vector_norm)
print('Senior Data Scientist to Data Scientist Similarity:', nlp(aam.loc[0,'job_title']).similarity(nlp('DATA SCIENTIST')))
# print('DATA SCIENTIST:',nlp('DATA SCIENTIST').vector)
SENIOR DATA SCIENTIST : 5.2609519574998
DATA SCIENTIST: 5.530525360918494
data scientist: 5.530525360918494
scientist data: 5.530525360918494
scientist: 7.720283285871691
DEBT ADVISOR: 6.803506150631042
Senior Data Scientist to Data Scientist Similarity: 0.9031808629204423
# Add vector to the data_set (SLOW)
aam['job_title_vector'] = aam['job_title'].apply(lambda x: nlp(str(x)).vector_norm)
search_vector_norm = aam.loc[0,'job_title_vector']
similarity_band = 0.001
print("0.001 Similarity:", np.unique(aam[(aam['job_title_vector'] <= search_vector_norm + similarity_band) \
& (aam['job_title_vector'] >= search_vector_norm - similarity_band)]['job_title']))
print("")
similarity_band = 0.005
print("0.005 Similarity:", np.unique(aam[(aam['job_title_vector'] <= search_vector_norm + similarity_band) \
& (aam['job_title_vector'] >= search_vector_norm - similarity_band)]['job_title']))
print("")
similarity_band = 0.01
print("0.01 Similarity:", np.unique(aam[(aam['job_title_vector'] <= search_vector_norm + similarity_band) \
& (aam['job_title_vector'] >= search_vector_norm - similarity_band)]['job_title']))
0.001 Similarity: ['ACCOUNTING ADMINISTRATIVE ASSISTANT' 'BOOKKEEPER/PAYROLL'
'INSTRUCTIONAL SYSTEMS SPECIALIST' 'INSTRUCTIONAL TECHNOLOGY SPECIALIST'
'PRINCIPAL RATE ANALYST' 'SENIOR DATA SCIENTIST' 'STRATEGY SUPERVISOR'
'SUBCONTRACTS MANAGEMENT']
0.005 Similarity: ['ACCOUNTING ADMINISTRATIVE ASSISTANT' 'ADMINISTRATIVE COORDINATOR'
'AP MANAGER' 'APPLICATIONS ENGINEER' 'APPLICATIONS SPECIALIST'
'BOOKKEEPER/PAYROLL' 'CLINICAL RESEARCH ANALYST'
'CLINICAL RESEARCH MANAGER' 'CLINICAL STUDY MANAGER'
'COMMUNICATIONS ASSOCIATE' 'COMMUNICATIONS CONSULTANT'
'COMMUNICATIONS SPECIALIST' 'COMPUTER ENGINEER' 'DISTRIBUTION CONSULTANT'
'DISTRIBUTION DESIGNER' 'ELECTRICAL ENGINEER' 'ELECTRONICS ENGINEER'
'ENGINEERING CONSULTANT' 'ENGINEERING PSYCHOLOGIST'
'ENGINEERING SPECIALIST' 'ENVIRONMENT CONSULTANT' 'FISH BIOLOGIST'
'HARDWARE ENGINEER' 'HSE MANAGER' 'INDUSTRIAL DESIGNER'
'INDUSTRIAL ENGINEER' 'INFRASTRUCTURE CONSULTANT'
'INFRASTRUCTURE ENGINEER' 'INSTRUCTIONAL SYSTEMS SPECIALIST'
'INSTRUCTIONAL TECHNOLOGY SPECIALIST' 'INTERNAL CONSULTANT'
'INVENTORY CLERK' 'LIGHTING DESIGNER' 'MARKETING CLERK' 'NICU NURSE'
'PHYSICS TEACHER' 'PRETREATMENT MANAGER' 'PRINCIPAL RATE ANALYST'
'PROGRAMS ASSOCIATE' 'PROJECT CONTROLS' 'RESEARCH PROGRAM ASSOCIATE'
'RESEARCH VETERINARIAN' 'SENIOR DATA SCIENTIST'
'SENIOR GLOBAL PROGRAM MANAGER' 'SENIOR SOFTWARE APPLICATION DEVELOPER'
'SOFTWARE ARCHITECT' 'SOFTWARE CONSULTANT' 'SOFTWARE DESIGNER'
'SOFTWARE ENGINEER' 'SOFTWARE TRAINER' 'STRATEGY SUPERVISOR'
'SUBCONTRACTS MANAGEMENT' 'SYSTEM ARCHITECT' 'SYSTEM ENGINEER'
'SYSTEM SPECIALIST' 'SYSTEMS ARCHITECT' 'SYSTEMS ENGINEER'
'TECHNOLOGY SPECIALIST' 'YOUTH LIBRARIAN']
0.01 Similarity: ['ACADEMY DIRECTOR' 'ACCOUNTING ADMINISTRATIVE ASSISTANT'
'ADMINISTRATIVE COORDINATOR' 'AP MANAGER' 'APPLICATIONS ENGINEER'
'APPLICATIONS SPECIALIST' 'ASSOCIATE DATA ANALYST' 'ASYLUM OFFICER'
'AVP DISTRIBUTION' 'BID ASSISTANT' 'BOOKKEEPER/PAYROLL' 'CINEMA MANAGER'
'CLINICAL RESEARCH ANALYST' 'CLINICAL RESEARCH MANAGER'
'CLINICAL STUDY MANAGER' 'COMMUNICATION CONSULTANT'
'COMMUNICATION INSTRUCTOR' 'COMMUNICATION SPECIALIST'
'COMMUNICATIONS ASSOCIATE' 'COMMUNICATIONS CONSULTANT'
'COMMUNICATIONS SPECIALIST' 'COMPUTER ENGINEER' 'CONSUMER INSIGHTS'
'CONTRACTS COORDINATOR' 'CURATORIAL ASSISTANT' 'DAIRY MANAGER'
'DECEDENT SPECIALIST' 'DENTAL ASSISTANT' 'DEPARTMENTAL ASSISTANT'
'DISTRIBUTION CONSULTANT' 'DISTRIBUTION DESIGNER' 'ELECTRICAL ENGINEER'
'ELECTRONICS ENGINEER' 'ENGINEERING CONSULTANT'
'ENGINEERING PSYCHOLOGIST' 'ENGINEERING SPECIALIST'
'ENGINEERING TECHNICIAN' 'ENVIRONMENT CONSULTANT' 'EXPERIENCE MANAGER'
'FIELD DIRECTOR' 'FISH BIOLOGIST' 'FLIGHT ATTENDANT' 'GLOBAL SOCIAL LEAD'
'GRADUATE STUDENT' 'GRAPHICS INTERN' 'HABITAT SURVEYOR'
'HARDWARE ENGINEER' 'HEALTH RESEARCH ANALYST' 'HOUSE MANAGER'
'HSE MANAGER' 'IMMIGRATION OFFICER' 'INDUSTRIAL DESIGNER'
'INDUSTRIAL ENGINEER' 'INFRASTRUCTURE CONSULTANT'
'INFRASTRUCTURE ENGINEER' 'INSTRUCTIONAL SYSTEMS SPECIALIST'
'INSTRUCTIONAL TECHNOLOGY SPECIALIST' 'INTERNAL CONSULTANT'
'INVENTORY CLERK' 'IT LEAD' 'LEAD BUSINESS ANALYST'
'LEAD FINANCIAL ANALYST' 'LIGHTING DESIGNER' 'LOGISTICS COORDINATOR'
'MARKETING CLERK' 'MASTER DATA ANALYST' 'MEETINGS MANAGER' 'NICU NURSE'
'NURSE NAVIGATOR' 'OPERATIONS COORDINATOR' 'PATIENT NAVIGATOR'
'PC TECHNICIAN' 'PERSONNEL COORDINATOR' 'PHYSICS TEACHER' 'PILOT MANAGER'
'PRETREATMENT MANAGER' 'PREVENTION SPECIALIST' 'PRINCIPAL RATE ANALYST'
'PRINCIPAL SERVICE MANAGER' 'PROGRAMS ASSOCIATE' 'PROJECT CONTROLS'
'RENEWABLE ENERGY PROGRAM MANAGER' 'RESEARCH PROGRAM ASSOCIATE'
'RESEARCH VETERINARIAN' 'RISK SPECIALIST' 'SAFETY CONSULTANT'
'SAFETY ENGINEER' 'SENIOR CUSTOMER EXPERIENCE ANALYST'
'SENIOR DATA ENGINEER' 'SENIOR DATA PLANNER' 'SENIOR DATA SCIENTIST'
'SENIOR GLOBAL PROGRAM MANAGER' 'SENIOR SOFTWARE APPLICATION DEVELOPER'
'SOFTWARE ARCHITECT' 'SOFTWARE CONSULTANT' 'SOFTWARE DESIGNER'
'SOFTWARE ENGINEER' 'SOFTWARE TRAINER' 'SPANISH INTERPRETER'
'STRATEGIC PRICING MANAGER' 'STRATEGY SUPERVISOR'
'SUBCONTRACTS MANAGEMENT' 'SYSTEM ARCHITECT' 'SYSTEM ENGINEER'
'SYSTEM SPECIALIST' 'SYSTEMS ARCHITECT' 'SYSTEMS ENGINEER'
'SYSTEMS MECHANIC' 'SYSTEMS TECHNICIAN' 'TECHNOLOGY SPECIALIST'
'TECHNOLOGY TECHNICIAN' 'TELEVISION DIRECTOR' 'WEALTH MANAGER'
'WELLNESS DIRECTOR' 'YOUTH LIBRARIAN']
# Add vector to the data_set (SLOW)
aam['combined_title'] = aam['industry'] + ' ' + aam['functional_area'] + ' ' + aam['job_title']
aam['combined_title_vector'] = aam['combined_title'].apply(lambda x: nlp(str(x)).vector_norm)
search_vector_norm = aam.loc[0,'combined_title_vector']
similarity_band = 0.0005
print("0.0005 Similarity:", np.unique(aam[(aam['combined_title_vector'] <= search_vector_norm + similarity_band) \
& (aam['combined_title_vector'] >= search_vector_norm - similarity_band)]['job_title']))
print("")
similarity_band = 0.001
print("0.001 Similarity:", np.unique(aam[(aam['combined_title_vector'] <= search_vector_norm + similarity_band) \
& (aam['combined_title_vector'] >= search_vector_norm - similarity_band)]['job_title']))
# print("")
# similarity_band = 0.005
# print("0.005 Similarity:", np.unique(aam[(aam['combined_title_vector'] <= search_vector_norm + similarity_band) \
# & (aam['combined_title_vector'] >= search_vector_norm - similarity_band)]['job_title']))
0.0005 Similarity: ['ASSISTANT DIRECTOR' 'DEPUTY PRESS SECRETARY'
'DIRECTOR OF DATA AND ANALYTICS' 'DIRECTOR OF GRANTS AND PROPOSALS'
'DIRECTOR OF MEDICAL EDUCATION' 'EDUCATION & CURRICULUM CONSULTANT'
'EDUCATION PROGRAMS COORDINATOR' 'EXECUTIVE ASSISTANT'
'FINANCIAL ANALYST II' 'IT ASSET MANAGEMENT'
'JUNIOR SOFTWARE SYSTEMS ENGINEER' 'LEAD ASSOCIATE'
'MANAGER, CHANGE MANAGEMENT' 'PEOPLE AND CULTURE ASSOCIATE'
'POLICY ANALYST' 'PRINCIPAL DATA SCIENTIST'
'PSYCHOTHERAPIST/TRAINING COORDINATOR'
'SALES SPECIALIST - OE AUTOMOTIVE PARTS MANUFACTURER'
'SENIOR ADVISOR SUPPORT ASSOCIATE'
'SENIOR CONSULTANT - CORPORATE SERVICES' 'SENIOR COORDINATOR'
'SENIOR DATA SCIENTIST' 'SOFTWARE ENGINEER 2'
'SYSTEMS ADMINISTRATOR LEAD' 'TITLE ONE TEACHER' 'VP/BSA OFFICER']
0.001 Similarity: ['ADJUNCT/CONTRACT FACULTY' 'ASSISTANT DIRECTOR'
'ASSOCIATE MARKETING MANAGER' 'COMMUNITY OUTREACH'
'COORDINATOR OF GRADUATE AFFAIRS' 'CURRICULUM WRITER' 'DATA ANALYST'
'DEPUTY PRESS SECRETARY' 'DIRECTOR OF DATA AND ANALYTICS'
'DIRECTOR OF GRANTS AND PROPOSALS' 'DIRECTOR OF MEDICAL EDUCATION'
'DISABILITY SERVICES DIRECTOR' 'EDUCATION & CURRICULUM CONSULTANT'
'EDUCATION PROGRAMS COORDINATOR' 'ENROLLMENT SERVICES MANAGER'
'EXECUTIVE ASSISTANT' 'FINANCIAL ANALYST II' 'IT ASSET MANAGEMENT'
'JUNIOR SOFTWARE SYSTEMS ENGINEER' 'LEAD ASSOCIATE'
'MANAGER, CHANGE MANAGEMENT' 'PEOPLE AND CULTURE ASSOCIATE'
'POLICY ANALYST' 'PRINCIPAL DATA SCIENTIST'
'PRINCIPAL USER ASSISTANCE CONSTULTANT' 'PRODUCT DESIGNER'
'PROJECT COORDINATOR' 'PSYCHOTHERAPIST/TRAINING COORDINATOR'
'SALES SPECIALIST - OE AUTOMOTIVE PARTS MANUFACTURER'
'SENIOR ADVISOR SUPPORT ASSOCIATE' 'SENIOR BENEFITS SPECIALIST'
'SENIOR BUSINESS ANALYST' 'SENIOR CONSULTANT - CORPORATE SERVICES'
'SENIOR COORDINATOR' 'SENIOR DATA SCIENTIST' 'SENIOR PROJECT MANAGER'
'SOFTWARE ENGINEER 2' 'SR DATA AND ANALYTICS PRODUCT MANAGER'
'SW ENGINEER' 'SYSTEMS ADMINISTRATOR LEAD' 'TITLE ONE TEACHER'
'VP/BSA OFFICER']
While the above shows good results, we cannot use the vectors themselves, as they are numeric, and thus in a model would indicate ordinality.
Clustering to Proxy Job Title
In order to reduce the number of unique job titles, we will attempt to ‘cluster’ the data based on some relevant job (columns). The above example showed how the text vectorization, while a good start, was not completely accurate. Adding education, total gross salary, and other important dimensions should help cluster job titles better than going just by title.
K-Means with Computed Vectors
We will start by using K-Means to cluster an aggregated version of the dataset with the above vectors.
During testing (not shown here), we averaged all relevant fields by job title to reduce the overall dataset for processing reasons; unfortunately, we could not aggregate categorical variables like industry, functional area, work type, and others without running the risk of clustering two job titles in multiple clusters. Similarly, due to the differences in currency, the subset of data used for this classification was in USD. While this methods did produce promising results, using combined title caused overlap in clusters with job titles. This is not ideal, as we want job title to be the main dividing factor between the clusters.
As such, the clustering will omit any variable that is not job title or is not a derivation of job title.
We will begin with creating a data processing pipeline to process the data for the model.
# Preprocessing Data Pipeline
numeric_features = ['job_title_vector']
numeric_transformer = Pipeline( #no missing values, so no need for an imputer
steps=[('scaler', StandardScaler())]
)
preprocessor = ColumnTransformer(
transformers = [
('num', numeric_transformer, numeric_features)
]
)
first_pipeline = Pipeline(
steps=[('preprocessor', preprocessor)
], verbose=True
)
K-Means First Test
Clustering, especially on this much data and creating 2,500 clusters takes a bit to run. In order to test and validate results without running the algorithm on the full dataset, we will take a subset (1,000 rows to 20 clusters) and observe the results.
# hmm.Subset Data, Transform
aam_subset = aam.loc[0:999]
aam_cluster = aam_subset
aam_cluster = aam_cluster[['job_title','age_group_o','exp_group_o','exp_field_group_o',
'education_o','total_gross_salary','job_title_vector',
'combined_title_vector']]
aam_cluster = aam_cluster.groupby(['job_title'], as_index=False).mean()
# Data Pipeline and Fit K-Means Model
test_df1 = first_pipeline.fit_transform(aam_cluster)
first_model = KMeans(n_clusters=20).fit(test_df1)
pickle.dump(first_model, open('kmeans_first_test_model.sav', 'wb')) #save model?
aam_cluster = aam_cluster.assign(cluster = first_model.labels_)
[Pipeline] ...... (step 1 of 1) Processing preprocessor, total= 0.0s
We can now see what job titles the model has grouped together.
# Creating Cluster Lists
cluster_list = []
for i in range(20):
exec("cluster_%d = []" % (i))
exec("cluster_%d = np.unique(aam_cluster[aam_cluster['cluster'] == %d]['job_title'])" % (i,i))
exec("cluster_list.append(cluster_%d)" % (i))
# Checking for Duplicates
overlap = []
for i in range(len(cluster_list)-1):
for j in range(i+1,20-i):
if len(set(cluster_list[i]) & set(cluster_list[j])) > 1:
overlap.append([i,j,set(cluster_list[i]) & set(cluster_list[j])])
overlap
cluster_list
Expand
``` [array(['ADMIN ASSISTANT', 'ADMINISTRATIVE OFFICER', 'ADULT AND TEEN LIBRARIAN', 'ANALOG ENGINEER', 'ASSISTANT FACILITIES MANAGER', 'ASSOCIATE EDITOR', 'ASSOCIATE VICE PRESIDENT', 'BENEFITS ANALYST', 'BILLING COORDINATOR', 'BUYER III', 'CHIEF ASSISTANT PUBLIC DEFENDER', 'CHIEF FINANCIAL OFFICER', 'CLIENT EXPERIENCE SPECIALIST', 'CLINICAL OPERATIONS MANAGER', 'CONTENT DESIGNER', 'CONTENT SPECIALIST', 'CREDENTIALING SPECIALIST', 'CREDIT UNION MANAGER', 'DATA PRODUCT CONSULTANT', 'DEPARTMENT HEAD', 'DIGITAL MARKETING MANAGER', 'DIRECTOR OF TECHNICAL SERVICES', 'ECONOMIC DEVELOPMENT SPECIALIST', 'ENERGY POLICY ANALYST', 'EVENT MANAGER', 'GENERAL MANAGER', 'GRANT OFFICER', 'HR ADVISOR', 'HR DIRECTOR', 'HR MANAGER', 'INDIRECT LOAN OFFICER', 'INFORMATION SECURITY ANALYST', 'INSIDE SALES', 'INTERNAL COMMUNICATION MANAGER', 'IT MANAGER', 'LEGAL TRANSLATOR', 'LIBRARY ASSOCIATE', 'LIBRARY SPECIALIST', 'MANAGER NEW PRODUCT DEVELOPMENT', 'MANAGING EDITOR', 'MARKETING VP', 'MIDDLE SCHOOL ENGLISH TEACHER', 'MUSIC TEACHER', 'NURSE PRACTITIONER', 'PARTNER MARKETING MANAGER', 'PAYROLL COORDINATOR', 'PEOPLE DEVELOPMENT PARTNER', 'PMO WIRELINE ANALYST', 'PRESS SECRETARY', 'PROCUREMENT AND CONTRACTS MANAGER', 'PRODUCT MARKETING SPECIALIST', 'PRODUCTION MANAGER', 'PROJECT MANAGER', 'PROPOSAL COORDINATOR', 'PROSPECT RESEARCH ANALYST', 'REFERRAL COORDINATOR', 'SCIENTIST I', 'SENIOR APPIAN DEVELOPER', 'SENIOR ASSOCIATE APPLICATION SPECIALIST', 'SENIOR CREATIVE DESIGNER', 'SENIOR FRONTEND DEVELOPER', 'SENIOR LITIGATION PARALEGAL', 'SENIOR MANAGER, BUSINESS SOLUTIONS', 'SENIOR MANAGING EDITOR', 'SENIOR POLICY PLANNER', 'SIGNAL ENGINEER', 'SPORTS REPORTER', 'STAFF ATTORNEY', 'TEACHING PROFESSOR', 'TEAM LEADER', 'TECHNICAL ACCOUNT MANAGER', 'TRADEMARK PARALEGAL', 'WEB COMMUNICATIONS ADVISOR'], dtype=object), array(['ACCOUNTS PAYABLE', 'DEBT ADVISOR', 'GRANTS', 'MATH TEACHER', 'MORTGAGE UNDERWRITER', 'PARTNER', 'PHYSICIAN', 'PRODUCER', 'TAX ACCOUNTANT', 'TEACHER'], dtype=object), array(['"NICHE SOFTWARE" SPECIALIST', 'ACCOUNT MANAGER/CLIENT RELATIONSHIPS', 'ACCOUNTANT (IN HOUSE)', 'ACCOUNTANT - ADVANCED', 'ACCOUNTING & MARKETING EXEC', 'ADJUNCT REFERENCE LIBRARIAN', 'ASSISTANT MANAGER, HEALTH RECORDS', 'ASSISTANT PROFESSOR OF MUSICOLOGY', 'ASSOCIATE SCIENTIST 1', 'AUTOMATION TEST ENGINEER 2', 'CUSTOMER SERVICE CALL CENTER SUPERVISOR', 'DEVELOPMENT & COMMUNICATIONS COORDINATOR', 'DIRECTOR OF EVENTS & MARKETING', 'DIRECTOR OF EVENTS AND PROGRAMS', 'DIRECTOR OF INSTITUTIONAL RESEARCH/REGISTRAR', 'DIRECTOR, DIRECT RESPONSE FUNDRAISING', 'DIRECTOR, ENGAGEMENT & STRATEGIC INITIATIVES', 'DIRECTOR, PEOPLE OPERATIONS', 'E-COMMERCE MANAGER', 'FRONTEND WEB DEVELOPER', 'GROUP MANAGER PROJECT MANAGEMENT', 'HELP DESK REPRESENTATIVE', 'IT EDP', 'JR. RESEARCH ASSOCIATE', 'LEARNING & DEVELOPMENT FACILITATOR', 'MOTION & GRAPHIC DESIGNER', 'PROGRAMMER ANALYST 2', 'PROGRAMMER ANALYST 3', 'PROJECT COORDINATOR, MATERIALS DEVELOPMENT', 'PROJECT MANAGER, ENERGY IMPLEMENTATION', 'PROJECT/PROGRAM MANAGER', 'RECRUITMENT & RETENTION SPECIALIST', 'RESEARCH COORDINATOR - SENIOR', 'SENIOR DIRECTOR, STRATEGY & OPERATIONS', 'SENIOR ENGINEER SPECIALIST - NETWORK OPERATIONS', 'SENIOR FINANCIAL ANALYIST', 'SENIOR SUPERVISOR, DEVELOPMENT', 'SENIOR VICE PRESIDENT & ASSOCIATE GENERAL COUNSEL', 'SPEECH-LANGUAGE PATHOLOGIST', 'SR. COMMUNICATIONS MANAGER', 'SR. COMPENSATION ANALYST', 'SR. COMPLIANCE ANALYST', 'SR. CONTENT MARKETING MANAGER', 'SR. CONTENT SPECIALIST', 'SR. PROJECT MANAGER', 'SR. SCRUM MASTER', 'SYSTEM LEVEL CLINICAL NURSE SPECIALIST', 'TEACHER/HEAD OF DEPARTMENT', 'VP, PRODUCT MANAGEMENT', 'YOUTH AND FAMILY PROGRAMS MANAGER'], dtype=object), array(['ACCOUNTS MANAGER', 'ACCOUNTS PAYABLE MANAGER', 'ADMINISTRATIVE ASSISTANT', 'ART DIRECTOR', 'ASSISTANT CONTROLLER', 'ASSOCIATE CHEMIST', 'BROKER RELATIONSHIP MANAGER', 'BUSINESS DEVELOPMENT MANAGER', 'BUSINESS INTELLIGENCE MANAGER', 'BUSINESS OPERATIONS MANAGER', 'CASE MANAGER', 'COMMUNICATIONS DIRECTOR', 'COMMUNICATIONS EXECUTIVE', 'COMMUNICATIONS MANAGER', 'COMPENSATION ANALYST', 'COMPUTATIONAL SCIENTIST', 'CORPORATE ATTORNEY', 'DATA SCIENTIST', 'DATABASE ADMINISTRATOR', 'EMPLOYABILITY MANAGER', 'ENGINEERING MANAGER', 'EXECUTIVE DIRECTOR STRATEGIC INITIATIVES', 'GRAPHICS ARTIST', 'HIGH SCHOOL TEACHER', 'INFRASTRUCTURE ENGINEERING SENIOR MANAGER', 'LAW CLERK', 'LEAD ANALYST', 'LEGAL ASSISTANT', 'LIFESTYLE DIRECTOR', 'MAINTENANCE MANAGER', 'MARKETING PRODUCER', 'MATHEMATICAL STATISTICIAN', 'OFFICE MANAGER', 'ORACLE CLOUD CONSULTANT', 'PATENT EXAMINER', 'PLANT BREEDER', 'POLICY ANALYST', 'POLICY LEAD', 'POSTGRADUATE ASSOCIATE', 'PRACTICE MANAGER', 'PRINCIPAL PRODUCT MANAGER', 'PRINCIPAL RECRUITER', 'PROCESS DEVELOPER', 'PRODUCT DESIGNER', 'PROGRAM ADMINISTRATOR', 'PROGRAM ASSISTANT', 'PURCHASING AGENT', 'RELOCATION CONSULTANT', 'REVENUE CYCLE MANAGER', 'SALES REP', 'SCIENCE INSTRUCTOR', 'SCIENTIFIC PROGRAMMER', 'SENIOR POLICY ADVISOR', 'SENIOR RECRUITER', 'SENIOR REGULATORY AFFAIRS SPECIALIST', 'SENIOR RESEARCH ASSOCIATE', 'SOFTWARE DEVELOPER', 'STAFF PARALEGAL', 'STAFF SCIENTIST', 'SUPERVISION PRINCIPAL', 'SYSTEMS ANALYST', 'TECHNICAL SPECIALIST', 'TECHNICAL TRAINER', 'TEST ENGINEER', 'TRAINING MANAGER', 'UTILITIES ANALYST', 'VICE PRESIDENT'], dtype=object), array(['MERCHANISER', 'TAXONOMIST'], dtype=object), array(['ADVISOR & PROGRAM MANAGER', 'ASSISTANT DIRECTOR OF ACADEMIC ADVISING', 'ASSISTANT DIRECTOR, OPERATIONS', 'ASSOCIATE COPY CHIEF', 'ASSOCIATE IRB CHAIR', 'ASSOCIATE PROFESSOR OF HISTORY', 'AUTONOMY ROBOTICS ENGINEER', 'CLIENT EXPERIENCE COACH', 'COMMUNITY ENGAGEMENT COORDINATOR', 'COMMUNITY ENGAGEMENT LIBRARIAN', 'COMPLIANCE AND REGULATORY ADVOCACY COORDINATOR', 'CONSTRUCTION DOCUMENT CONTROL MANAGER', 'CUSTOMER SERVICE CLERK', 'CUSTOMER SUCCESS MANAGER', 'DIRECTOR OF ANNUAL GIVING', 'DIRECTOR OF PROSPECT RESEARCH', 'DIRECTOR OF REHABILITATION SERVICES', 'DIRECTOR OF SUPPORT', 'DIRECTOR OF TRUST AND SAFETY', 'DIRECTOR, FINANCE AND ADMINISTRATION', 'EVENT SERVICES COORDINATOR', 'HEAD OF ENGINEERING', 'HEAD OF PROPOSALS', 'HEARING INSTRUMENT SPECIALIST', 'HR GENERALIST', 'HR SPECIALIST', 'HUMAN RESOURCES DIRECTOR', 'HUMAN RESOURCES MANAGER', 'HUMAN RESOURCES SPECIALIST', 'INVENTORY ACCURACY COORDINATOR', 'LEAD GAME DESIGNER', 'LIBRARIAN DEPARTMENT HEAD', 'LIBRARIAN, BRANCH MANAGER', 'LIBRARY ACCESS SERVICES MANAGER', 'MANAGER OF INFORMATION SERVICES', 'MANAGER OF POLICY AND ADVOCACY', 'MANAGER, ACCOUNTING & FINANCE', 'MANAGER, DOCUMENT CONTROL', 'MANAGER, STRATEGY', 'MARKETING CONTENT SPECIALIST', 'MEMBER DATA SPECIALIST', 'MICROBIAL/CHEMICAL TECHNOLOGIST', 'PARK OPERATIONS SUPERVISOR', 'PAYROLL & INVOICING CLERK', 'PEOPLE OPERATIONS MANAGER', 'POSTDOCTORAL RESEARCH ASSOCIATE', 'PROFESSOR OF CHEMISTRY', 'PROGRAM ANALYST I', 'PROJECT SUPPORT ANALYST', 'PROMOTION REVIEW EDITOR', 'RECORDS PROJECT MANAGER', 'RECRUITER IN HOUSE', 'REGISTERED CLINICAL NURSE', 'RESOURCE SOIL SCIENTIST', 'SENIOR CUSTOMER SUCCESS CONSULTANT', 'SENIOR MOTION GRAPHICS DESIGNER', 'SENIOR OFFICER, FINANCE', 'SENIOR PUBLIC RELATIONS & AFFAIRS SPECIALIST', 'SITE RELIABILITY ENGINEER', 'SOFTWARE ENGINEER I', 'SOFTWARE SUPPORT MANAGER', 'SR SOFTWARE ENGINEER', 'SR. DIRECTOR', 'STAFF WRITER', 'SUPPLY CHAIN COORDINATOR', 'TUTOR/NANNY', 'UPPER SCHOOL LIBRARIAN', 'VALET OPERATIONS MANAGER', 'VIRTUAL CONTENT MANAGER', 'WORKDAY PROJECT MANAGER', 'WRITING CENTER DIRECTOR', 'YOUTH SERVICES LIBRARIAN'], dtype=object), array(['ASSISTANT PROVOST; DIRECTOR, CENTER FOR FACULTY EXCELLENCE', 'BSA/AML/ OFAC ADMINISTRATOR', 'CHIEF OF STAFF (DEPUTY DIRECTOR)', 'CUSTOMER SERVICE REP-UNLICENSED', 'DEPUTY DIRECTOR, EVENTS & ATTENDEE EXPERIENCE', 'DEPUTY EDITOR/GRAPHIC DESIGN', "EXECUTIVE VICE PRESIDENT/MARKET RESEARCH, GENERAL MANAGER (OF A RESEARCH FIRM THAT'S A WHOLLY-OWNED SUBSIDIARY OF MY LARGER COMPANY)", 'GEOSPATIAL SERVICE COORDINATOR', 'MANAGER OF NEURODIAGNOSTICS', 'MANAGER, ENGINERING', 'RECORDS MANAGEMENT CLERK 1', 'SALES CO-ORDINATOR', 'SR DIRECTOR, PRESALES'], dtype=object), array(['ARCHIVIST', 'ASTRONOMER', 'BOOKSELLER', 'COPYWRITER', 'EPIDEMIOLOGIST', 'MICROBIOLOGIST', 'PHARMACIST', 'PHYSICIST', 'STATISTICIAN'], dtype=object), array(['ACCOUNTS ASSISTANT', 'ADVOCATE MANAGER', 'ASSISTANT DIRECTOR', 'ASSOCIATE DIRECTOR', 'BRANCH CHIEF', 'CHIEF ENGINEER', 'CLINICAL TECHNOLOGIST', 'COORDINATOR', 'DATA ANALYST', 'DATA MANAGER', 'EXECUTIVE ASSISTANT', 'EXECUTIVE UNDERWRITER', 'FINANCIAL ASSISTANT', 'FUNDING MANAGER', 'PAYROLL ANALYST', 'PAYROLL MANAGER', 'PROPERTY ACCOUNTANT', 'QA ANALYST', 'REVENUE ANALYST', 'REVENUE MANAGER', 'SENIOR ACCOUNTANT', 'SENIOR ADMINISTRATOR', 'SENIOR ASSOCIATE', 'SENIOR COMPLIANCE ANALYST', 'SENIOR DATABASE ANALYST', 'SENIOR INSTRUCTOR', 'SENIOR JOURNALIST', 'SENIOR PLANNER', 'SENIOR POLICY ANALYST', 'SENIOR PROGRAM MANAGER', 'SENIOR REPORTER', 'TAX SENIOR MANAGER', 'WEALTH ADVISOR'], dtype=object), array(['ACCOUNT EXECUTIVE', 'ACCOUNT MANAGER', 'ACCOUNTING ASSOCIATE', 'ADMINISTRATIVE COORDINATOR', 'APPLICATIONS ENGINEER', 'ASSISTANT BRANCH MANAGER', 'BIOMEDICAL ENGINEER', 'BUSINESS APPLICATIONS ANALYST', 'BUSINESS COMPLIANCE MANAGER', 'BUSINESS INITIATIVES MANAGER', 'BUSINESS SYSTEMS ANALYST', 'CIVIL ENGINEER', 'COMMUNICATION SPECIALIST', 'COMMUNICATIONS ADMINISTRATOR', 'COMMUNICATIONS SPECIALIST', 'CONTENT STRATEGIST', 'CREATIVE DIRECTOR', 'CURATORIAL ASSISTANT', 'CUSTOMER SERVICE', 'DATA ENGINEER', 'DEPARTMENTAL ANALYST', 'DIGITAL COMMUNICATIONS MANAGER', 'DIGITAL DESIGNER', 'EDITORIAL DIRECTOR', 'ELECTRICAL ENGINEER', 'ELECTRONICS ENGINEER', 'ENGINEERING ASSISTANT', 'ENGINEERING PSYCHOLOGIST', 'ENROLLMENT MANAGER', 'ENVIRONMENTAL ENGINEER', 'EVENTS MANAGER', 'EXPO MANAGER', 'GRANTS MANAGER', 'HUMAN RESOURCES', 'INTEGRITY ENGINEER', 'INTERNAL AUDITOR', 'LAB ASSISTANT', 'LAW PROFESSOR', 'LEAD UNDERWRITER', 'LEGAL SECRETARY', 'LOGISTICS COORDINATOR', 'LOGISTICS SUPERVISOR', 'MEDICAL LIBRARIAN', 'OPERATIONS COORDINATOR', 'PERSONAL LOAN SPECIALIST', 'PRACTICE COORDINATOR', 'PRETREATMENT MANAGER', 'PROGRAM ASSOCIATE', 'PROGRAM SPECIALIST SENIOR', 'PROPOSAL SPECIALIST', 'PUBLIC SERVICE ADMINISTRATOR', 'REIMBURSEMENT DIRECTOR', 'RESEARCH ASSISTANT', 'RESEARCH ASSOCIATE', 'SCIENCE TEACHER', 'SENIOR AUDITOR', 'SENIOR DATA ENGINEER', 'SENIOR DATA SCIENTIST', 'SENIOR DIGITAL MARKETING EXECUTIVE', 'SENIOR DIRECTOR, ADVISOR', 'SENIOR LEARNING SPECIALIST', 'SENIOR REPRESENTATIVE', 'SENIOR RESEARCH SCIENTIST', 'SOFTWARE ENGINEER', 'SYSTEM ARCHITECT', 'SYSTEM ENGINEER', 'SYSTEMS ADMINISTRATOR', 'SYSTEMS ENGINEER', 'TRAINING SERVICES CONSULTANT', 'TREASURY ACCOUNTING SPECIALIST', 'UX DESIGNER', 'UX RESEARCHER'], dtype=object), array(['ANALYST', 'CONTROLLER', 'DIRECTOR', 'DJ', 'ESTIMATOR', 'EXECUTIVE DIRECTOR', 'MANAGER', 'PROGRAMMER', 'RN', 'SENIOR ANALYST', 'SENIOR DEVELOPER', 'SENIOR MANAGER'], dtype=object), array(['ADMINISTRATIVE ASSISTANT - ADVANCED', 'ASSISSTANT DIRECTOR', 'ASSISTANT PAC COORDINATOR', 'ASSOCIATE DIRECTOR OF ALUMNI AND DONOR RELATIONS', 'CASE MANAGER - EMPLOYMENT SERVICES', 'CITY PLANNING CONSULTANT (ASSOCIATE DIRECTOR)', 'DIRECTOR OF CATALOGING & METADATA', 'ENGLISH TEACHER (YEAR 16)', 'GEOBASE ANALYST', 'GRANTS & COMPLIANCE MANAGER', 'GRANTS & CONTENT MANAGER', 'HELPDESK OPERATOR', 'HR/BENEFITS COORDINATOR', 'IN HOUSE COUNSEL FOR A MAJOR NON-PROFIT', 'IN-HOUSE COUNSEL', 'LAWYER (PARTNER)', 'LEAN SIX SIGMA BLACKBELT', 'LEGAL ASSISTANT/JUNIOR EDITOR', 'REGISTERED DIETITIAN', 'RESEARCH TECHNICIAN 2', 'SENIOR COORDINATOR, FUNDRAISING ANALYTICS', 'STRATEGY & COMMUNICATIONS INTERN', 'TEACHER/CAMPUS MINISTER', 'TELEHEALTH PROGRAM MANAGER', 'VP, EVENTS MANAGER'], dtype=object), array(['ACADEMIC ADVISOR AND LECTURER', 'ADMINISTRATIVE ASSISTANT 2', 'AUTO CLAIMS ADJUSTER BODILY INJURY', 'BILLING SPECIALIST TEAM LEAD', 'CASE MANAGER/PARALEGAL', 'CHIEF NURSING INFORMATICS OFFICER', 'CHIEF OF STAFF', 'CHIEF PHILANTHROPY OFFICER', 'CITY COUNCIL COORDINATOR', 'COMMUNICATIONS & MARKETING MANAGER', 'COMPLIANCE AND SCHEDULE MANAGER', 'CONTACT TRACING DATA ADMINISTRATOR', 'CONTENT STRATEGIST/CONTENT DESIGNER', 'DEPUTY ATTORNEY GENERAL', 'DIRECTOR OF ADVANCEMENT COMMUNICATIONS', 'DIRECTOR OF ALUMNI ENGAGEMENT', 'DIRECTOR OF DONOR STEWARDSHIP', 'DIRECTOR OF ENROLLMENT MANAGEMENT', 'DIRECTOR OF FINANCE AND HR', 'DIRECTOR OF OPERATIONS AND MARKETING COMMUNICATIONS', 'DIRECTOR OF PURCHASING AND CONTRACTS', 'DIRECTOR OF QUALITY AND SAFETY', 'DIRECTOR, RESOURCE DEVELOPMENT', 'FRAUD AND PHYSICAL SECURITY SUPERVISOR', 'HEALTH PROGRAM ADMINISTRATOR 2', 'HUMAN RESOURCES ANALYST A', 'INFORMATION MANAGEMENT SPECIALIST', 'INTERNAL MEDICINE-PCP', 'IT PROJECT MANAGER', 'IT SUPPORT SPECIALIST', 'JUNIOR CIVIL ENGINEER', 'LEAD HR SPECIALIST', 'LEAD NOISE AND VIBRATION PERFORMANCE ENGINEER', 'LEARNING & DEVELOPMENT MANAGER', 'LEARNING AND TEACHING ADMINISTRATOR', 'LEARNING SUPPORT SUPERVISOR', 'LIBRARY CIRCULATION MANAGER', 'MANAGEMENT AND PROGRAM ANALYST', 'MANAGER OF DATA AND PROSPECT RESEARCH', 'OPEN SOURCE ANALYST', 'OPERATIONS & MARKETING MANAGER', 'PRICIPAL PROFESSIONAL ENGINEER', 'PROGRAMME MANAGEMENT OFFICE MANAGER', 'PROGRAMMER TEAM LEAD', 'PROSPECT MANAGEMENT ANALYST', 'QUALITY MANAGER/DESIGN ENGINEER', 'RECRUITMENT AND MARKETING COORDINATOR', 'RESEARCH ASSOCIATE 1', 'RESEARCH SCIENTIST IV', 'REVIEWER AND TEAM LEAD', 'SENIOR HUMAN RESOURCES ASSISTANT', 'SENIOR MANAGER, PROGRAMMATIC ADVERTISING', 'SENIOR MANAGER, RESOURCE STRATEGY', 'SENIOR QUALITY CONTROL ASSOCIATE SCIENTIST', 'SENIOR WRITER/EDITOR', 'SHIPPING/RECEIVING ADMIN', 'SOFTWARE DEVELOPMENT ENGINEER IN TEST', 'SPECIAL EDUCATION/MATH TEACHER', 'SR DATA AND ANALYTICS PRODUCT MANAGER', 'SR. PRODUCT MANAGER', 'SR. SCIENTIST', 'SR. TECHNICAL SPECIALIST', 'STORE GENERAL MANAGER', 'STUDENT INFORMATION SYSTEM SUPPORT SPECIALIST', 'SYSTEMS AND SUPPORT MANAGER', 'SYSTEMS RELIABILITY AND SUPPORT SPECIALIST', 'TECHNOLOGY AND INNOVATION COORDINATOR', 'VP OF ENGINEERING', 'VP OF MARKETING', 'VP OF OPERATIONS'], dtype=object), array(['ACADEMIC ADVISOR', 'AML INVESTIGATOR', 'ANALYTICS DATA ENGINEER', 'ASSISTANT PROFESSOR', 'ASSISTANT PROPERTY MANAGER', 'ASSOCIATE ATTORNEY', 'ATTORNEY III', 'AUTOMATION ENGINEER', 'BRAND MANAGER', 'BUSINESS PERFORMANCE ANALYST', 'CLINICAL NEUROPSYCHOLOGIST', 'CLINICAL PHYSICIST', 'CLINICAL THERAPIST', 'COMPLIANCE ASSOCIATE', 'CONTRACT ENGAGEMENT MANAGER', 'DATA COORDINATOR', 'DATA REVIEWER', 'DESIGN ENGINEER', 'DEVELOPMENT ASSOCIATE', 'DEVELOPMENT COORDINATOR', 'DIRECTOR OF ACCOUNTING', 'DIRECTOR OF FINANCE', 'DIRECTOR OF PLANNING', 'DISTRICT DATA MANAGER', 'EDUCATION COORDINATOR', 'ELECTRONICS ENGINEER SENIOR', 'EPIDEMIOLOGIST II', 'GRAPHIC DESIGNER', 'HEAD GARDENER', 'IMPLEMENTATION CONSULTANT', 'INSTRUCTION LIBRARIAN', 'LAB TECHNICIAN', 'LABORATORY GENETIC COUNSELOR', 'LIBRARY DIRECTOR', 'LOAN OFFICER ASSISTANT', 'MARKETING SPECIALIST', 'MECHANICAL ENGINEER', 'MEDICAL SCRIBE', 'OPERATIONS ASSOCIATE', 'PAYROLL AND FINANCE ADMINISTRATOR', 'PLANT PLANNER', 'PRACTICE ADMINISTRATOR', 'PRINCIPAL SCIENTIST', 'PRODUCT DESIGN SENIOR MANAGER', 'PROGRAM COORDINATOR', 'PROJECT ASSISTANT', 'PUBLIC ART MANAGER', 'RECREATION THERAPIST', 'RESEARCH CHEMIST', 'SALES ASSOCIATE', 'SCIENCE TECHNICIAN', 'SENIOR COMMUNICATIONS SPECIALIST', 'SENIOR COORDINATOR', 'SENIOR DEVELOPMENT ASSOCIATE', 'SENIOR DEVELOPMENT PROJECT MANAGER', 'SENIOR ENGINEERING SPECIALIST', 'SENIOR HEALTH RESEARCHER', 'SENIOR SOFTWARE ENGINEER', 'SENIOR SYSTEMS ENGINEER', 'SERVICE DESIGNER', 'SERVICE SPECIALIST', 'SOCIAL RESEARCHER', 'SOFTWARE PROGRAM MANAGER', 'SOLUTION ENGINEER', 'SPEECH LANGUAGE PATHOLOGIST', 'STAFF ASSOCIATE', 'STORE MANAGER', 'SYSTEMS LIBRARIAN', 'TEACHING ASSISTANT', 'TRANSITION REPRESENTATIVE', 'UX RESEARCH MANAGER'], dtype=object), array(['1X1 COORDINATOR', 'ADMINISTRATIVE ASSISTANT IV', 'ARCHIVES ASSOCIATE', 'ART AIDE', 'ASSOCIATE CAPITAL PROJECT ANALYST', 'ASSOCIATE GENERAL COUNSEL', 'BRANCH OPERATIONS SUPERVISOR', 'CASH APPLICATION SPECIALIST', 'CHIEF DEVELOPMENT OFFICER', 'COMMS CONSULTANT', 'CONTENT MARKETING MANAGER', 'CONTENT PRODUCER', 'CREATIVE CONTENT WRITER', 'CRIME SCENE INVESTIGATOR', 'CUSTOMER SERVICE REPRESENTATIVE', 'CUSTOMER SERVICE SPECIALIST', 'CYBER DEFENCE ENGINEER', 'DIRECTOR OF APPLICATIONS', 'DIRECTOR OF COMMUNICATIONS', 'DIRECTOR OF DEVELOPMENT OPERATIONS', 'DIRECTOR OF OPERATIONS', 'DIRECTOR OF PROGRAM DEVELOPMENT', 'DIRECTOR OF SCHEDULING', 'DIRECTOR OF STUDENT SERVICES', 'FUNDRAISING DATA ANALYST', 'GAME DESIGNER', 'GRADUATE RESEARCH ASSISTANT', 'HEAD OF ACCESSIBILITY', 'HEALTH CARE ADVOCATE', 'HEALTH IT CONSULTANT', 'HR BUSINESS PARTNER', 'HR CLERICAL ASSISTANT', 'HUMAN RESOURCES ASSISTANT', 'HUMAN RESOURCES BUSINESS PARTNER', 'INFORMATION AND PROGRAM MANAGER', 'INSIDE SALES MANAGER', 'INSTRUCTIONAL DESIGN MANAGER', 'IT COMMUNICATIONS MANAGER', 'IT SPECIALIST', 'JOURNALS PRODUCTION COORDINATOR', 'JUNIOR SOFTWARE ENGINEER', 'LEAD PROCESS ENGINEER', 'LEAD SERVICE DESIGNER', 'LEARNING AND PERFORMANCE CONSULTANT', 'MANAGER, STRATEGIC MESSAGING', 'MARKET RESEARCH PROJECT MANAGER', 'MEDICAL EDITOR', 'MEDICAL LABORATORY SCIENTIST', 'MEDICAL WRITER', 'METADATA LIBRARIAN', 'NATIONAL TRAINING MANAGER', 'NETWORK RELATIONS SPECIALIST', 'NURSE CLINICIAN', 'PARTNER RELATIONSHIP AND MARKETING MANAGER', 'PEER SUPPORT', 'PRINCIPLE DATA SCIENTIST', 'PRODUCT SUPPORT MANAGER', 'PRODUCTION EDITOR', 'REFERENCE LIBRARIAN', 'REGIONAL SALES MANAGER', 'RESEARCH ADMINISTRATOR SR', 'RLA TEACHER', 'SCHOLARSHIP COUNSELOR', 'SEARCH COORDINATOR', 'SENIOR QUALITY ASSURANCE ENGINEER', 'SENIOR SCIENTIST I', 'SR PROGRAM MANAGER', 'SR. PHARMACY CONSULTANT', 'SUPPLY CHAIN PLANNER', 'TECHNICAL WRITING MANAGER', 'VOLUNTEER COORDINATOR', 'VOLUNTEER SCREENING MANAGER', 'WHOLESALE OPERATIONS MANAGER'], dtype=object), array(['ACCOUNTING MANAGER', 'ACTUARIAL ANALYST', 'ADJUNCT', 'ASSET MANAGER', 'ASSOCIATE', 'ASSOCIATE PROFESSOR', 'BUSINESS ANALYST', 'BUSINESS MANAGER', 'CONSULTANT', 'FINANCE MANAGER', 'FINANCIAL ANALYST', 'FIRM MANAGER', 'FISCAL ANALYST', 'INSIGHTS ANALYST', 'LECTURER', 'MANAGING DIRECTOR', 'PROFESSIONAL ENGINEER', 'PROFESSOR', 'PSYCHOTHERAPIST', 'REPORTER', 'RESEARCH DIRECTOR', 'RESEARCH MANAGER', 'RESEARCHER', 'SENIOR CHEMIST', 'SENIOR INSTITUTIONAL ANALYST', 'SENIOR MARKETING MANAGER', 'SENIOR RESEARCH ANALYST', 'SENIOR SCIENTIST', 'SUPERVISOR', 'TECHNICIAN'], dtype=object), array(['ACCOUNTANT', 'ADMINISTRATOR', 'ATTORNEY', 'AUDITOR', 'BARRISTER', 'BOOKKEEPER', 'BUYER', 'CEO', 'CLERK', 'LIBRARIAN', 'PARALEGAL', 'RECRUITER', 'TUTOR'], dtype=object), array(['401(K) ANALYST', 'CEDENTIALING COORDINATOR', 'CLIENT PLAFORM ENGINEER/TIER 3 SUPPORT', 'CYBERSECURITY ENGINEER', 'IT HELPDESK ENGINEER', 'PREDOCTORAL CURRICULUM COORDINATOR AND PROGRAM ADMINISTRATOR, MMSC IN DENTAL EDUCATION', 'R&D ASSOCIATE', 'SALESFORCE CONSULTANT'], dtype=object), array(['ANALYTICS MANAGER', 'CONTENT EDITOR', 'CONTENT WRITER', 'CYBER SECURITY', 'DEPARTMENT MANAGER', 'DEVELOPMENT ACCOUNTANT', 'DEVELOPMENT DIRECTOR', 'DEVELOPMENT MANAGER', 'EDITOR', 'ENTERPRISE SOLUTIONS ARCHITECT', 'FISHERY ANALYST', 'INSTRUCTIONAL DESIGNER', 'INSTRUCTIONAL TECHNOLOGIST', 'LABORATORY ANALYST', 'LEARNING SPECIALIST', 'LEASING ADMINISTRATOR', 'MARKETING DIRECTOR', 'MARKETING MANAGER', 'MRO BUSINESS OWNER', 'OPERATIONS MANAGER', 'PARTNER MANAGER', 'PRODUCT MANAGER', 'PRODUCT OWNER', 'PROGRAM ANALYST', 'PROGRAM DIRECTOR', 'PROGRAM MANAGER', 'PROPERTY MANAGER', 'PROPOSAL MANAGER', 'RESEARCH TECHNOLOGIST', 'SALES DIRECTOR', 'SENIOR ADMINISTRATIVE ANALYST', 'SENIOR ART DIRECTOR', 'SENIOR ASSOCIATE CONSULTANT', 'SENIOR BUSINESS INTELLIGENCE DEVELOPER', 'SENIOR PARTNER', 'SENIOR RESOURCE ANALYST', 'SOFTWARE ENGINEERING MANAGER', 'SOLUTIONS MANAGER', 'STAFF ACCOUNTANT', 'TECHNICAL DIRECTOR', 'TECHNICAL SERVICES DIRECTOR', 'WEB DEVELOPER'], dtype=object), array(['ACADEMIC COORDINATOR', 'ACADEMIC PROGRAM MANAGER', 'ADJUNCT PROFESSOR', 'ADMINISTRATIVE SERVICES ASSOCIATE', 'ASSISTANT COORDINATOR', 'ASSOCIATE DIRECTOR CORPORATE INSURANCE', 'ASSOCIATE PROVOST', 'CERTIFIED ANESTHESIOLOGIST ASSISTANT', 'CIRCULATION COORDINATOR', 'CLINICAL LABORATORY SCIENTIST', 'CLINICAL TRIAL MANAGER', 'CONTROLLING SPECIALIST', 'CUSTODIAN OF RECORDS', 'DEPUTY CHIEF COUNSEL', 'DIRECTOR LOYALTY MARKETING', 'DIRECTOR OF DEVELOPMENT', 'DIRECTOR OF HARDWARE ENGINEERING', 'DIRECTOR OF MULTIFAMILY HOUSING DEVELOPMENT', 'DIRECTOR, BUSINESS DEVELOPMENT', 'DISTILLERY SUPERVISOR', 'ENGINEER II', 'FOREIGN SERVICE OFFICER', 'INVOICING ADMIN', 'IP SPECIALIST', 'JOB COORDINATOR', 'LEAD PROGRAM ARCHITECT', 'LEARNING AND DEVELOPMENT LEAD', 'LEARNING ENGAGEMENT ASSOCIATE', 'LEGAL EDITOR', 'LEGISLATIVE AFFAIRS ASSOCIATE', 'PHD STUDENT', 'PHILANTHROPY ASSOCIATE', 'PHYSICAL SCIENTIST', 'PRINCIPAL NETWORK ENGINEER', 'PRINCIPAL QUALITY ENGINEER', 'PRODUCTION PROCESS LEAD', 'PROJECT COORDINATOR', 'REGIONAL ADMINISTRATOR', 'RESEARCH PROJECT DIRECTOR', 'SALES ADMINISTRATIVE ASSISTANT', 'SECTION HEAD', 'SENIOR APPLICATION PROGRAMMER', 'SENIOR DIRECTOR OF IT', 'SENIOR GIS SPECIALIST', 'SENIOR STATISTICAL OFFICER', 'SERVICE COORDINATOR', 'SR PRODUCT MANAGER', 'STUDENT EMPLOYMENT SUPERVISOR', 'TECHNICAL WRITER', 'WEB ACCESSIBILITY EVALUATOR'], dtype=object)] ```While it did look to group fairly equally, some job titles don’t really belong together. Luckily, there is another method built into scikit learn.
K-Means Second Test
In the sci-kit learn library, there are built in functions to process text. One string to vector transformer is the FeatureHasher, which can turn a string into a matrix with a set number of features. Below, the pipeline has been rebuilt using the FeatureHasher instead of the string vectors.
# Preprocessing Data Pipeline
preprocessor = ColumnTransformer(
transformers = [
# ('num', numeric_transformer, numeric_features),
('str1', FeatureHasher(input_type='string', n_features=1000), 'job_title')
# ('str2', FeatureHasher(input_type='string', n_features=1000), 'combined_title')
]
)
second_pipeline = Pipeline(
steps=[('preprocessor', preprocessor)
], verbose=True
)
# K-Means Cluster
aam_subset = aam.loc[0:999]
aam_cluster2 = aam_subset
aam_cluster2 = aam_cluster2[['job_title','age_group_o','exp_group_o','exp_field_group_o',
'education_o','total_gross_salary']]
aam_cluster2 = aam_cluster2.groupby(['job_title'], as_index=False).median()
test_df2 = second_pipeline.fit_transform(aam_cluster2)
cluster_model = KMeans(n_clusters=20).fit(test_df2)
pickle.dump(cluster_model, open('kmeans_second_test_model.sav', 'wb')) #save model?
aam_cluster2 = aam_cluster2.assign(cluster = cluster_model.labels_)
[Pipeline] ...... (step 1 of 1) Processing preprocessor, total= 0.0s
We can now see what job titles the model has grouped together.
# Creating Cluster Lists
cluster_list = []
for i in range(20):
exec("cluster_%d = []" % (i))
exec("cluster_%d = np.unique(aam_cluster2[aam_cluster2['cluster'] == %d]['job_title'])" % (i,i))
exec("cluster_list.append(cluster_%d)" % (i))
# Checking for Duplicates
overlap = []
for i in range(len(cluster_list)-1):
for j in range(i+1,20-i):
if len(set(cluster_list[i]) & set(cluster_list[j])) > 1:
overlap.append([i,j,set(cluster_list[i]) & set(cluster_list[j])])
overlap
cluster_list
Expand
``` [array(['ACADEMIC ADVISOR', 'ADJUNCT', 'ADJUNCT PROFESSOR', 'ADMINISTRATOR', 'ARCHIVIST', 'ART AIDE', 'ASSOCIATE', 'ASTRONOMER', 'ATTORNEY', 'ATTORNEY III', 'AUDITOR', 'BARRISTER', 'BOOKKEEPER', 'BOOKSELLER', 'BRANCH CHIEF', 'BUYER', 'BUYER III', 'CEO', 'CHIEF OF STAFF', 'CLERK', 'CONSULTANT', 'CONTROLLER', 'COORDINATOR', 'COPYWRITER', 'DEBT ADVISOR', 'DIRECTOR', 'DJ', 'EDITOR', 'EPIDEMIOLOGIST', 'ESTIMATOR', 'GRANT OFFICER', 'GRANTS', 'HR ADVISOR', 'HR SPECIALIST', 'IN-HOUSE COUNSEL', 'IT EDP', 'LAW CLERK', 'LAW PROFESSOR', 'LECTURER', 'LEGAL EDITOR', 'LIBRARIAN', 'MARKETING VP', 'MICROBIOLOGIST', 'PARTNER', 'PEER SUPPORT', 'PHARMACIST', 'PHD STUDENT', 'PHYSICIAN', 'PHYSICIST', 'POLICY LEAD', 'PRODUCER', 'PRODUCT OWNER', 'PROFESSOR', 'PROGRAMMER', 'PSYCHOTHERAPIST', 'R&D ASSOCIATE', 'REPORTER', 'RN', 'SALES REP', 'SECTION HEAD', 'SENIOR AUDITOR', 'SENIOR JOURNALIST', 'STAFF WRITER', 'SUPERVISOR', 'TAXONOMIST', 'TEACHER', 'TECHNICIAN', 'TUTOR', 'TUTOR/NANNY', 'UX DESIGNER', 'VP OF MARKETING', 'VP OF OPERATIONS', 'WEALTH ADVISOR'], dtype=object), array(['ASSOCIATE DIRECTOR CORPORATE INSURANCE', 'ASSOCIATE DIRECTOR OF ALUMNI AND DONOR RELATIONS', 'CITY PLANNING CONSULTANT (ASSOCIATE DIRECTOR)', 'COMMUNITY ENGAGEMENT COORDINATOR', 'COMPLIANCE AND REGULATORY ADVOCACY COORDINATOR', 'CONSTRUCTION DOCUMENT CONTROL MANAGER', 'CONTACT TRACING DATA ADMINISTRATOR', 'DEVELOPMENT & COMMUNICATIONS COORDINATOR', 'DIRECTOR OF ADVANCEMENT COMMUNICATIONS', 'DIRECTOR OF MULTIFAMILY HOUSING DEVELOPMENT', 'DIRECTOR OF OPERATIONS AND MARKETING COMMUNICATIONS', 'DIRECTOR OF PURCHASING AND CONTRACTS', 'DIRECTOR, FINANCE AND ADMINISTRATION', 'IN HOUSE COUNSEL FOR A MAJOR NON-PROFIT', 'INVENTORY ACCURACY COORDINATOR', 'PROJECT COORDINATOR, MATERIALS DEVELOPMENT', 'RECRUITMENT AND MARKETING COORDINATOR', 'SENIOR COORDINATOR, FUNDRAISING ANALYTICS', 'STRATEGY & COMMUNICATIONS INTERN', 'TECHNOLOGY AND INNOVATION COORDINATOR'], dtype=object), array(['ASSISTANT MANAGER, HEALTH RECORDS', 'ASSISTANT PROFESSOR OF MUSICOLOGY', 'ASSOCIATE GENERAL COUNSEL', 'ASSOCIATE PROFESSOR', 'ASSOCIATE PROFESSOR OF HISTORY', 'BRANCH OPERATIONS SUPERVISOR', 'BUSINESS COMPLIANCE MANAGER', 'BUSINESS OPERATIONS MANAGER', 'BUSINESS PERFORMANCE ANALYST', 'CUSTOMER SERVICE SPECIALIST', 'CUSTOMER SUCCESS MANAGER', 'DIRECTOR OF PROSPECT RESEARCH', 'FRAUD AND PHYSICAL SECURITY SUPERVISOR', 'GRADUATE RESEARCH ASSISTANT', 'HR BUSINESS PARTNER', 'HUMAN RESOURCES ANALYST A', 'HUMAN RESOURCES ASSISTANT', 'HUMAN RESOURCES BUSINESS PARTNER', 'HUMAN RESOURCES DIRECTOR', 'HUMAN RESOURCES SPECIALIST', 'JR. RESEARCH ASSOCIATE', 'LEARNING SUPPORT SUPERVISOR', 'LIBRARY ACCESS SERVICES MANAGER', 'MRO BUSINESS OWNER', 'PARK OPERATIONS SUPERVISOR', 'POSTDOCTORAL RESEARCH ASSOCIATE', 'PROFESSOR OF CHEMISTRY', 'PROGRAM SPECIALIST SENIOR', 'PROSPECT RESEARCH ANALYST', 'RESEARCH ADMINISTRATOR SR', 'RESEARCH ASSOCIATE', 'RESEARCH ASSOCIATE 1', 'RESOURCE SOIL SCIENTIST', 'SCHOLARSHIP COUNSELOR', 'SENIOR CUSTOMER SUCCESS CONSULTANT', 'SENIOR HUMAN RESOURCES ASSISTANT', 'SENIOR MANAGER, BUSINESS SOLUTIONS', 'SENIOR RESEARCH ANALYST', 'SENIOR RESEARCH ASSOCIATE', 'SENIOR RESEARCH SCIENTIST', 'SENIOR RESOURCE ANALYST', 'SR DIRECTOR, PRESALES', 'SYSTEMS AND SUPPORT MANAGER', 'YOUTH SERVICES LIBRARIAN'], dtype=object), array(['ACADEMIC ADVISOR AND LECTURER', 'ADULT AND TEEN LIBRARIAN', 'ANALYTICS DATA ENGINEER', 'ASSISTANT BRANCH MANAGER', 'AUTO CLAIMS ADJUSTER BODILY INJURY', 'BSA/AML/ OFAC ADMINISTRATOR', 'CLINICAL OPERATIONS MANAGER', 'CLINICAL TRIAL MANAGER', 'COMMUNICATIONS ADMINISTRATOR', 'COMMUNICATIONS MANAGER', 'CREDIT UNION MANAGER', 'DATABASE ADMINISTRATOR', 'DIGITAL COMMUNICATIONS MANAGER', 'DIGITAL MARKETING MANAGER', 'DIRECTOR OF ANNUAL GIVING', 'DISTRICT DATA MANAGER', 'FUNDRAISING DATA ANALYST', 'INFORMATION SECURITY ANALYST', 'INSTRUCTION LIBRARIAN', 'INSTRUCTIONAL DESIGN MANAGER', 'INTERNAL AUDITOR', 'INVOICING ADMIN', 'IT COMMUNICATIONS MANAGER', 'LEASING ADMINISTRATOR', 'LIBRARIAN DEPARTMENT HEAD', 'LIBRARIAN, BRANCH MANAGER', 'LIBRARY CIRCULATION MANAGER', 'MANAGER OF NEURODIAGNOSTICS', 'MEDICAL LIBRARIAN', 'METADATA LIBRARIAN', 'NATIONAL TRAINING MANAGER', 'PAYROLL AND FINANCE ADMINISTRATOR', 'PRACTICE ADMINISTRATOR', 'REGIONAL ADMINISTRATOR', 'SENIOR ADMINISTRATOR', 'SENIOR FINANCIAL ANALYIST', 'SENIOR LITIGATION PARALEGAL', 'SENIOR MANAGING EDITOR', 'SR. COMMUNICATIONS MANAGER', 'TECHNICAL WRITING MANAGER'], dtype=object), array(['"NICHE SOFTWARE" SPECIALIST', 'ASSOCIATE COPY CHIEF', 'ASSOCIATE IRB CHAIR', 'BILLING SPECIALIST TEAM LEAD', 'CASH APPLICATION SPECIALIST', 'CLINICAL LABORATORY SCIENTIST', 'CLINICAL NEUROPSYCHOLOGIST', 'CLINICAL PHYSICIST', 'CLINICAL TECHNOLOGIST', 'CLINICAL THERAPIST', 'COMMUNICATION SPECIALIST', 'COMMUNICATIONS SPECIALIST', 'COMPLIANCE ASSOCIATE', 'COMPUTATIONAL SCIENTIST', 'CONTENT SPECIALIST', 'CONTROLLING SPECIALIST', 'EPIDEMIOLOGIST II', 'HEAD OF ACCESSIBILITY', 'HR CLERICAL ASSISTANT', 'INSTRUCTIONAL TECHNOLOGIST', 'IP SPECIALIST', 'IT SPECIALIST', 'IT SUPPORT SPECIALIST', 'LEAD HR SPECIALIST', 'LEAN SIX SIGMA BLACKBELT', 'LEARNING SPECIALIST', 'LIBRARY SPECIALIST', 'LOGISTICS SUPERVISOR', 'MARKETING SPECIALIST', 'MEDICAL LABORATORY SCIENTIST', 'MEMBER DATA SPECIALIST', 'MICROBIAL/CHEMICAL TECHNOLOGIST', 'NETWORK RELATIONS SPECIALIST', 'PERSONAL LOAN SPECIALIST', 'PHILANTHROPY ASSOCIATE', 'PHYSICAL SCIENTIST', 'PRINCIPAL SCIENTIST', 'PRINCIPLE DATA SCIENTIST', 'PRODUCT MARKETING SPECIALIST', 'PROPOSAL SPECIALIST', 'PUBLIC SERVICE ADMINISTRATOR', 'SCIENTIST I', 'SENIOR COMPLIANCE ANALYST', 'SENIOR GIS SPECIALIST', 'SENIOR STATISTICAL OFFICER', 'SERVICE SPECIALIST', 'SPECIAL EDUCATION/MATH TEACHER', 'SR. CONTENT SPECIALIST', 'SR. TECHNICAL SPECIALIST', 'SUPERVISION PRINCIPAL', 'TECHNICAL SPECIALIST', 'UTILITIES ANALYST', 'WEB ACCESSIBILITY EVALUATOR'], dtype=object), array(['ACADEMIC PROGRAM MANAGER', 'ADVISOR & PROGRAM MANAGER', 'ASSISTANT PROPERTY MANAGER', 'BROKER RELATIONSHIP MANAGER', 'CASE MANAGER/PARALEGAL', 'HEALTH PROGRAM ADMINISTRATOR 2', 'HUMAN RESOURCES MANAGER', 'LEAD PROGRAM ARCHITECT', 'MARKET RESEARCH PROJECT MANAGER', 'OPERATIONS MANAGER', 'PEOPLE OPERATIONS MANAGER', 'PRINCIPAL PRODUCT MANAGER', 'PRODUCT SUPPORT MANAGER', 'PROGRAM ADMINISTRATOR', 'PROGRAM ASSOCIATE', 'PROGRAM MANAGER', 'PROGRAMMER ANALYST 2', 'PROGRAMMER ANALYST 3', 'PROGRAMMER TEAM LEAD', 'PROJECT/PROGRAM MANAGER', 'PROPERTY MANAGER', 'PROPOSAL MANAGER', 'RECORDS PROJECT MANAGER', 'SENIOR APPLICATION PROGRAMMER', 'SENIOR PROGRAM MANAGER', 'SOFTWARE PROGRAM MANAGER', 'SOFTWARE SUPPORT MANAGER', 'SR PRODUCT MANAGER', 'SR PROGRAM MANAGER', 'SR. PRODUCT MANAGER', 'SR. PROJECT MANAGER', 'TELEHEALTH PROGRAM MANAGER', 'TRADEMARK PARALEGAL', 'VALET OPERATIONS MANAGER', 'WHOLESALE OPERATIONS MANAGER', 'WORKDAY PROJECT MANAGER'], dtype=object), array(['ACCOUNTS ASSISTANT', 'ADMIN ASSISTANT', 'ARCHIVES ASSOCIATE', 'ASSISSTANT DIRECTOR', 'ASSISTANT CONTROLLER', 'ASSISTANT COORDINATOR', 'ASSISTANT DIRECTOR', 'ASSISTANT PAC COORDINATOR', 'ASSISTANT PROFESSOR', 'ASSOCIATE ATTORNEY', 'ASSOCIATE CHEMIST', 'ASSOCIATE EDITOR', 'ASSOCIATE PROVOST', 'ASSOCIATE SCIENTIST 1', 'BUSINESS ANALYST', 'BUSINESS SYSTEMS ANALYST', 'CONTENT STRATEGIST', 'CURATORIAL ASSISTANT', 'DATA SCIENTIST', 'EXECUTIVE ASSISTANT', 'FINANCIAL ASSISTANT', 'GRAPHICS ARTIST', 'INSIDE SALES', 'INSIGHTS ANALYST', 'LAB ASSISTANT', 'LEGAL ASSISTANT', 'LIBRARY ASSOCIATE', 'LOAN OFFICER ASSISTANT', 'OPERATIONS ASSOCIATE', 'POSTGRADUATE ASSOCIATE', 'PROGRAM ASSISTANT', 'PROJECT ASSISTANT', 'RESEARCH ASSISTANT', 'SALES ASSOCIATE', 'SENIOR ASSOCIATE', 'SENIOR DATA SCIENTIST', 'SENIOR DATABASE ANALYST', 'SR. COMPENSATION ANALYST', 'SR. SCIENTIST', 'STAFF ASSOCIATE', 'STAFF SCIENTIST', 'STATISTICIAN', 'SYSTEMS ADMINISTRATOR', 'SYSTEMS ANALYST', 'SYSTEMS LIBRARIAN', 'TEACHING ASSISTANT'], dtype=object), array(["EXECUTIVE VICE PRESIDENT/MARKET RESEARCH, GENERAL MANAGER (OF A RESEARCH FIRM THAT'S A WHOLLY-OWNED SUBSIDIARY OF MY LARGER COMPANY)"], dtype=object), array(['ART DIRECTOR', 'ASSOCIATE DIRECTOR', 'CONTENT EDITOR', 'CONTENT PRODUCER', 'CONTENT WRITER', 'CREATIVE DIRECTOR', 'CUSTOMER SERVICE', 'CUSTOMER SERVICE CLERK', 'CYBER SECURITY', 'DATA REVIEWER', 'DEPUTY CHIEF COUNSEL', 'DISTILLERY SUPERVISOR', 'EXECUTIVE DIRECTOR', 'GRAPHIC DESIGNER', 'HELPDESK OPERATOR', 'HIGH SCHOOL TEACHER', 'HR DIRECTOR', 'HR GENERALIST', 'HUMAN RESOURCES', 'LEAD UNDERWRITER', 'LEGAL SECRETARY', 'LIBRARY DIRECTOR', 'LIFESTYLE DIRECTOR', 'MARKETING DIRECTOR', 'MARKETING PRODUCER', 'MATH TEACHER', 'MEDICAL EDITOR', 'MEDICAL SCRIBE', 'MEDICAL WRITER', 'MERCHANISER', 'MORTGAGE UNDERWRITER', 'MUSIC TEACHER', 'NURSE PRACTITIONER', 'PLANT BREEDER', 'PRESS SECRETARY', 'PRINCIPAL RECRUITER', 'PRODUCT DESIGNER', 'PROGRAM DIRECTOR', 'RECREATION THERAPIST', 'RECRUITER', 'RECRUITER IN HOUSE', 'REIMBURSEMENT DIRECTOR', 'RESEARCH CHEMIST', 'RESEARCH DIRECTOR', 'RESEARCH PROJECT DIRECTOR', 'RESEARCH TECHNOLOGIST', 'RESEARCHER', 'RLA TEACHER', 'SALES DIRECTOR', 'SCIENCE INSTRUCTOR', 'SCIENCE TEACHER', 'SCIENTIFIC PROGRAMMER', 'SENIOR CHEMIST', 'SENIOR PARTNER', 'SENIOR RECRUITER', 'SENIOR REPORTER', 'SENIOR WRITER/EDITOR', 'SOCIAL RESEARCHER', 'SPORTS REPORTER', 'SR. DIRECTOR', 'SR. SCRUM MASTER', 'SYSTEM ARCHITECT', 'TEACHER/CAMPUS MINISTER', 'TEACHING PROFESSOR', 'TECHNICAL DIRECTOR', 'TECHNICAL TRAINER', 'TECHNICAL WRITER', 'UX RESEARCHER', 'VICE PRESIDENT'], dtype=object), array(['ADJUNCT REFERENCE LIBRARIAN', 'AUTOMATION TEST ENGINEER 2', 'CASE MANAGER - EMPLOYMENT SERVICES', 'DIRECTOR OF ALUMNI ENGAGEMENT', 'DIRECTOR OF ENROLLMENT MANAGEMENT', 'DIRECTOR OF EVENTS & MARKETING', 'DIRECTOR OF HARDWARE ENGINEERING', 'ENVIRONMENTAL ENGINEER', 'INFRASTRUCTURE ENGINEERING SENIOR MANAGER', 'LEAD NOISE AND VIBRATION PERFORMANCE ENGINEER', 'LEARNING & DEVELOPMENT FACILITATOR', 'LEARNING & DEVELOPMENT MANAGER', 'LEARNING AND DEVELOPMENT LEAD', 'LEARNING ENGAGEMENT ASSOCIATE', 'MANAGER NEW PRODUCT DEVELOPMENT', 'PRODUCT DESIGN SENIOR MANAGER', 'PROJECT MANAGER, ENERGY IMPLEMENTATION', 'QUALITY MANAGER/DESIGN ENGINEER', 'RECORDS MANAGEMENT CLERK 1', 'SENIOR DEVELOPMENT PROJECT MANAGER', 'SENIOR MANAGER, RESOURCE STRATEGY', 'SENIOR QUALITY ASSURANCE ENGINEER', 'SOFTWARE ENGINEERING MANAGER', 'VOLUNTEER SCREENING MANAGER'], dtype=object), array(['ADMINISTRATIVE OFFICER', 'APPLICATIONS ENGINEER', 'ASSOCIATE VICE PRESIDENT', 'BIOMEDICAL ENGINEER', 'BUSINESS INTELLIGENCE MANAGER', 'CHIEF ASSISTANT PUBLIC DEFENDER', 'CHIEF FINANCIAL OFFICER', 'CHIEF NURSING INFORMATICS OFFICER', 'CIVIL ENGINEER', 'CLIENT EXPERIENCE COACH', 'CLIENT EXPERIENCE SPECIALIST', 'COMMUNICATIONS EXECUTIVE', 'CREDENTIALING SPECIALIST', 'CRIME SCENE INVESTIGATOR', 'DEPUTY EDITOR/GRAPHIC DESIGN', 'DIGITAL DESIGNER', 'DIRECTOR OF TECHNICAL SERVICES', 'ECONOMIC DEVELOPMENT SPECIALIST', 'ENGINEER II', 'ENGINEERING ASSISTANT', 'ENGINEERING PSYCHOLOGIST', 'HEARING INSTRUMENT SPECIALIST', 'INSTRUCTIONAL DESIGNER', 'INTEGRITY ENGINEER', 'INTERNAL MEDICINE-PCP', 'JUNIOR CIVIL ENGINEER', 'MARKETING CONTENT SPECIALIST', 'MECHANICAL ENGINEER', 'MIDDLE SCHOOL ENGLISH TEACHER', 'NURSE CLINICIAN', 'PRICIPAL PROFESSIONAL ENGINEER', 'PRINCIPAL NETWORK ENGINEER', 'PRINCIPAL QUALITY ENGINEER', 'REGISTERED CLINICAL NURSE', 'REGISTERED DIETITIAN', 'RESEARCH SCIENTIST IV', 'RESEARCH TECHNICIAN 2', 'SCIENCE TECHNICIAN', 'SENIOR DIGITAL MARKETING EXECUTIVE', 'SENIOR ENGINEERING SPECIALIST', 'SENIOR LEARNING SPECIALIST', 'SENIOR MOTION GRAPHICS DESIGNER', 'SENIOR OFFICER, FINANCE', 'SENIOR POLICY PLANNER', 'SENIOR SCIENTIST', 'SENIOR SCIENTIST I', 'SHIPPING/RECEIVING ADMIN', 'SITE RELIABILITY ENGINEER', 'TECHNICAL SERVICES DIRECTOR', 'TRAINING SERVICES CONSULTANT', 'TRANSITION REPRESENTATIVE', 'WRITING CENTER DIRECTOR'], dtype=object), array(['PREDOCTORAL CURRICULUM COORDINATOR AND PROGRAM ADMINISTRATOR, MMSC IN DENTAL EDUCATION'], dtype=object), array(['ADMINISTRATIVE ASSISTANT', 'ADMINISTRATIVE ASSISTANT - ADVANCED', 'ADMINISTRATIVE ASSISTANT 2', 'ADMINISTRATIVE ASSISTANT IV', 'ADMINISTRATIVE SERVICES ASSOCIATE', 'ASSISTANT DIRECTOR OF ACADEMIC ADVISING', 'ASSISTANT DIRECTOR, OPERATIONS', 'ASSISTANT FACILITIES MANAGER', 'ASSOCIATE CAPITAL PROJECT ANALYST', 'BUSINESS APPLICATIONS ANALYST', 'BUSINESS INITIATIVES MANAGER', 'CERTIFIED ANESTHESIOLOGIST ASSISTANT', 'LEGAL ASSISTANT/JUNIOR EDITOR', 'LEGISLATIVE AFFAIRS ASSOCIATE', 'MATHEMATICAL STATISTICIAN', 'SALES ADMINISTRATIVE ASSISTANT', 'SENIOR ADMINISTRATIVE ANALYST', 'SENIOR ASSOCIATE APPLICATION SPECIALIST', 'SENIOR ASSOCIATE CONSULTANT', 'SENIOR COMMUNICATIONS SPECIALIST', 'SENIOR INSTITUTIONAL ANALYST', 'SENIOR PUBLIC RELATIONS & AFFAIRS SPECIALIST', 'SENIOR QUALITY CONTROL ASSOCIATE SCIENTIST', 'SENIOR REGULATORY AFFAIRS SPECIALIST', 'STUDENT INFORMATION SYSTEM SUPPORT SPECIALIST', 'SYSTEM LEVEL CLINICAL NURSE SPECIALIST', 'SYSTEMS RELIABILITY AND SUPPORT SPECIALIST', 'TREASURY ACCOUNTING SPECIALIST'], dtype=object), array(['ADVOCATE MANAGER', 'ANALOG ENGINEER', 'ASSET MANAGER', 'AUTOMATION ENGINEER', 'BRAND MANAGER', 'BUSINESS MANAGER', 'CASE MANAGER', 'DATA ENGINEER', 'DATA MANAGER', 'DEPARTMENT HEAD', 'DEPARTMENT MANAGER', 'DEVELOPMENT MANAGER', 'E-COMMERCE MANAGER', 'ENGINEERING MANAGER', 'ENROLLMENT MANAGER', 'EVENT MANAGER', 'EVENTS MANAGER', 'EXPO MANAGER', 'FINANCE MANAGER', 'FIRM MANAGER', 'FUNDING MANAGER', 'GAME DESIGNER', 'GENERAL MANAGER', 'GRANTS MANAGER', 'HEAD GARDENER', 'HR MANAGER', 'INSIDE SALES MANAGER', 'IT MANAGER', 'IT PROJECT MANAGER', 'LAWYER (PARTNER)', 'LEAD GAME DESIGNER', 'MAINTENANCE MANAGER', 'MANAGER', 'MANAGER, ENGINERING', 'MANAGER, STRATEGY', 'MANAGING DIRECTOR', 'MANAGING EDITOR', 'MARKETING MANAGER', 'OFFICE MANAGER', 'PARTNER MANAGER', 'PATENT EXAMINER', 'PRACTICE MANAGER', 'PRETREATMENT MANAGER', 'PRODUCT MANAGER', 'PRODUCTION MANAGER', 'PROJECT MANAGER', 'PUBLIC ART MANAGER', 'PURCHASING AGENT', 'REGIONAL SALES MANAGER', 'RESEARCH MANAGER', 'REVENUE ANALYST', 'REVENUE MANAGER', 'SENIOR MANAGER', 'SENIOR PLANNER', 'SIGNAL ENGINEER', 'STORE GENERAL MANAGER', 'STORE MANAGER', 'TAX SENIOR MANAGER', 'TEAM LEADER', 'TRAINING MANAGER', 'UX RESEARCH MANAGER', 'VP, EVENTS MANAGER', 'VP, PRODUCT MANAGEMENT'], dtype=object), array(['ACCOUNT EXECUTIVE', 'ACCOUNT MANAGER', 'ACCOUNTANT', 'ACCOUNTANT (IN HOUSE)', 'ACCOUNTANT - ADVANCED', 'ACCOUNTING ASSOCIATE', 'ACCOUNTING MANAGER', 'ACCOUNTS MANAGER', 'ACCOUNTS PAYABLE MANAGER', 'COMMS CONSULTANT', 'DATA PRODUCT CONSULTANT', 'DEVELOPMENT ACCOUNTANT', 'HEALTH CARE ADVOCATE', 'HEALTH IT CONSULTANT', 'IMPLEMENTATION CONSULTANT', 'MANAGER, DOCUMENT CONTROL', 'ORACLE CLOUD CONSULTANT', 'PROPERTY ACCOUNTANT', 'RELOCATION CONSULTANT', 'SALESFORCE CONSULTANT', 'SENIOR ACCOUNTANT', 'SR. PHARMACY CONSULTANT', 'STAFF ACCOUNTANT', 'TAX ACCOUNTANT', 'TECHNICAL ACCOUNT MANAGER', 'VIRTUAL CONTENT MANAGER'], dtype=object), array(['401(K) ANALYST', 'ACCOUNTS PAYABLE', 'ACTUARIAL ANALYST', 'AML INVESTIGATOR', 'ANALYST', 'ANALYTICS MANAGER', 'BENEFITS ANALYST', 'COMPENSATION ANALYST', 'DATA ANALYST', 'DEPARTMENTAL ANALYST', 'EMPLOYABILITY MANAGER', 'ENERGY POLICY ANALYST', 'FINANCIAL ANALYST', 'FISCAL ANALYST', 'FISHERY ANALYST', 'GEOBASE ANALYST', 'HEAD OF PROPOSALS', 'LAB TECHNICIAN', 'LABORATORY ANALYST', 'LEAD ANALYST', 'LEGAL TRANSLATOR', 'OPEN SOURCE ANALYST', 'PARALEGAL', 'PAYROLL ANALYST', 'PAYROLL MANAGER', 'PLANT PLANNER', 'PMO WIRELINE ANALYST', 'POLICY ANALYST', 'PROGRAM ANALYST', 'PROGRAM ANALYST I', 'PROJECT SUPPORT ANALYST', 'QA ANALYST', 'SENIOR ANALYST', 'SENIOR POLICY ANALYST', 'SOLUTIONS MANAGER', 'SPEECH LANGUAGE PATHOLOGIST', 'SPEECH-LANGUAGE PATHOLOGIST', 'SR. COMPLIANCE ANALYST', 'STAFF ATTORNEY', 'STAFF PARALEGAL', 'SUPPLY CHAIN PLANNER'], dtype=object), array(['ACCOUNT MANAGER/CLIENT RELATIONSHIPS', 'ACCOUNTING & MARKETING EXEC', 'COMMUNICATIONS & MARKETING MANAGER', 'COMMUNITY ENGAGEMENT LIBRARIAN', 'COMPLIANCE AND SCHEDULE MANAGER', 'CONTENT MARKETING MANAGER', 'CONTRACT ENGAGEMENT MANAGER', 'DIRECTOR OF CATALOGING & METADATA', 'GRANTS & COMPLIANCE MANAGER', 'GRANTS & CONTENT MANAGER', 'GROUP MANAGER PROJECT MANAGEMENT', 'INFORMATION AND PROGRAM MANAGER', 'INFORMATION MANAGEMENT SPECIALIST', 'INTERNAL COMMUNICATION MANAGER', 'LEARNING AND PERFORMANCE CONSULTANT', 'LEARNING AND TEACHING ADMINISTRATOR', 'MANAGEMENT AND PROGRAM ANALYST', 'MANAGER OF DATA AND PROSPECT RESEARCH', 'MANAGER OF INFORMATION SERVICES', 'MANAGER OF POLICY AND ADVOCACY', 'MANAGER, ACCOUNTING & FINANCE', 'MANAGER, STRATEGIC MESSAGING', 'OPERATIONS & MARKETING MANAGER', 'PARTNER MARKETING MANAGER', 'PARTNER RELATIONSHIP AND MARKETING MANAGER', 'PROCUREMENT AND CONTRACTS MANAGER', 'PROGRAMME MANAGEMENT OFFICE MANAGER', 'PROSPECT MANAGEMENT ANALYST', 'SENIOR MANAGER, PROGRAMMATIC ADVERTISING', 'SENIOR MARKETING MANAGER', 'SR DATA AND ANALYTICS PRODUCT MANAGER', 'SR. CONTENT MARKETING MANAGER', 'YOUTH AND FAMILY PROGRAMS MANAGER'], dtype=object), array(['1X1 COORDINATOR', 'ACADEMIC COORDINATOR', 'ADMINISTRATIVE COORDINATOR', 'AUTONOMY ROBOTICS ENGINEER', 'BILLING COORDINATOR', 'CEDENTIALING COORDINATOR', 'CHIEF OF STAFF (DEPUTY DIRECTOR)', 'CHIEF PHILANTHROPY OFFICER', 'CIRCULATION COORDINATOR', 'CITY COUNCIL COORDINATOR', 'COMMUNICATIONS DIRECTOR', 'CORPORATE ATTORNEY', 'CUSTODIAN OF RECORDS', 'DATA COORDINATOR', 'DEVELOPMENT COORDINATOR', 'DIRECTOR LOYALTY MARKETING', 'DIRECTOR OF ACCOUNTING', 'DIRECTOR OF APPLICATIONS', 'DIRECTOR OF COMMUNICATIONS', 'DIRECTOR OF DONOR STEWARDSHIP', 'DIRECTOR OF EVENTS AND PROGRAMS', 'DIRECTOR OF FINANCE', 'DIRECTOR OF FINANCE AND HR', 'DIRECTOR OF OPERATIONS', 'DIRECTOR OF PLANNING', 'DIRECTOR OF PROGRAM DEVELOPMENT', 'DIRECTOR OF QUALITY AND SAFETY', 'DIRECTOR OF SCHEDULING', 'DIRECTOR OF SUPPORT', 'DIRECTOR OF TRUST AND SAFETY', 'DIRECTOR, PEOPLE OPERATIONS', 'EDITORIAL DIRECTOR', 'EDUCATION COORDINATOR', 'GEOSPATIAL SERVICE COORDINATOR', 'HR/BENEFITS COORDINATOR', 'INDIRECT LOAN OFFICER', 'JOB COORDINATOR', 'JOURNALS PRODUCTION COORDINATOR', 'LABORATORY GENETIC COUNSELOR', 'LOGISTICS COORDINATOR', 'MOTION & GRAPHIC DESIGNER', 'OPERATIONS COORDINATOR', 'PAYROLL & INVOICING CLERK', 'PAYROLL COORDINATOR', 'PRACTICE COORDINATOR', 'PRODUCTION EDITOR', 'PRODUCTION PROCESS LEAD', 'PROGRAM COORDINATOR', 'PROJECT COORDINATOR', 'PROMOTION REVIEW EDITOR', 'PROPOSAL COORDINATOR', 'REFERRAL COORDINATOR', 'RESEARCH COORDINATOR - SENIOR', 'SALES CO-ORDINATOR', 'SEARCH COORDINATOR', 'SENIOR ART DIRECTOR', 'SENIOR COORDINATOR', 'SENIOR DIRECTOR OF IT', 'SENIOR DIRECTOR, ADVISOR', 'SENIOR INSTRUCTOR', 'SENIOR POLICY ADVISOR', 'SERVICE COORDINATOR', 'SUPPLY CHAIN COORDINATOR', 'UPPER SCHOOL LIBRARIAN', 'VOLUNTEER COORDINATOR', 'WEB COMMUNICATIONS ADVISOR'], dtype=object), array(['ASSISTANT PROVOST; DIRECTOR, CENTER FOR FACULTY EXCELLENCE', 'CLIENT PLAFORM ENGINEER/TIER 3 SUPPORT', 'CONTENT STRATEGIST/CONTENT DESIGNER', 'CUSTOMER SERVICE CALL CENTER SUPERVISOR', 'CUSTOMER SERVICE REPRESENTATIVE', 'DEPUTY DIRECTOR, EVENTS & ATTENDEE EXPERIENCE', 'DIRECTOR OF DEVELOPMENT OPERATIONS', 'DIRECTOR OF INSTITUTIONAL RESEARCH/REGISTRAR', 'DIRECTOR OF REHABILITATION SERVICES', 'DIRECTOR, DIRECT RESPONSE FUNDRAISING', 'DIRECTOR, ENGAGEMENT & STRATEGIC INITIATIVES', 'ENTERPRISE SOLUTIONS ARCHITECT', 'EXECUTIVE DIRECTOR STRATEGIC INITIATIVES', 'RECRUITMENT & RETENTION SPECIALIST', 'SENIOR BUSINESS INTELLIGENCE DEVELOPER', 'SENIOR DIRECTOR, STRATEGY & OPERATIONS', 'SENIOR ENGINEER SPECIALIST - NETWORK OPERATIONS', 'SENIOR VICE PRESIDENT & ASSOCIATE GENERAL COUNSEL', 'SOFTWARE DEVELOPMENT ENGINEER IN TEST'], dtype=object), array(['BUSINESS DEVELOPMENT MANAGER', 'CHIEF DEVELOPMENT OFFICER', 'CHIEF ENGINEER', 'CONTENT DESIGNER', 'CREATIVE CONTENT WRITER', 'CUSTOMER SERVICE REP-UNLICENSED', 'CYBER DEFENCE ENGINEER', 'CYBERSECURITY ENGINEER', 'DEPUTY ATTORNEY GENERAL', 'DESIGN ENGINEER', 'DEVELOPMENT ASSOCIATE', 'DEVELOPMENT DIRECTOR', 'DIRECTOR OF DEVELOPMENT', 'DIRECTOR OF STUDENT SERVICES', 'DIRECTOR, BUSINESS DEVELOPMENT', 'DIRECTOR, RESOURCE DEVELOPMENT', 'ELECTRICAL ENGINEER', 'ELECTRONICS ENGINEER', 'ELECTRONICS ENGINEER SENIOR', 'ENGLISH TEACHER (YEAR 16)', 'EVENT SERVICES COORDINATOR', 'EXECUTIVE UNDERWRITER', 'FOREIGN SERVICE OFFICER', 'FRONTEND WEB DEVELOPER', 'HEAD OF ENGINEERING', 'HELP DESK REPRESENTATIVE', 'IT HELPDESK ENGINEER', 'JUNIOR SOFTWARE ENGINEER', 'LEAD PROCESS ENGINEER', 'LEAD SERVICE DESIGNER', 'PEOPLE DEVELOPMENT PARTNER', 'PROCESS DEVELOPER', 'PROFESSIONAL ENGINEER', 'REFERENCE LIBRARIAN', 'REVENUE CYCLE MANAGER', 'REVIEWER AND TEAM LEAD', 'SENIOR APPIAN DEVELOPER', 'SENIOR CREATIVE DESIGNER', 'SENIOR DATA ENGINEER', 'SENIOR DEVELOPER', 'SENIOR DEVELOPMENT ASSOCIATE', 'SENIOR FRONTEND DEVELOPER', 'SENIOR HEALTH RESEARCHER', 'SENIOR REPRESENTATIVE', 'SENIOR SOFTWARE ENGINEER', 'SENIOR SUPERVISOR, DEVELOPMENT', 'SENIOR SYSTEMS ENGINEER', 'SERVICE DESIGNER', 'SOFTWARE DEVELOPER', 'SOFTWARE ENGINEER', 'SOFTWARE ENGINEER I', 'SOLUTION ENGINEER', 'SR SOFTWARE ENGINEER', 'STUDENT EMPLOYMENT SUPERVISOR', 'SYSTEM ENGINEER', 'SYSTEMS ENGINEER', 'TEACHER/HEAD OF DEPARTMENT', 'TEST ENGINEER', 'VP OF ENGINEERING', 'WEB DEVELOPER'], dtype=object)] ```While still not perfect, these groups look better than the previous groupings.
Birch Third Test
We can additionally use the Birch model to cluster the data.
# birch
from sklearn.cluster import Birch
op_model = Birch(n_clusters = 20).fit(test_df2)
aam_cluster2 = aam_cluster2.assign(cluster3 = op_model.labels_)
cluster_list = []
for i in range(max(aam_cluster2['cluster3'])):
exec("cluster_%d = []" % (i))
exec("cluster_%d = np.unique(aam_cluster2[aam_cluster2['cluster3'] == %d]['job_title'])" % (i,i))
exec("cluster_list.append(cluster_%d)" % (i))
print(cluster_list)
Expand
``` [array(['ADMINISTRATIVE ASSISTANT', 'ADMINISTRATIVE ASSISTANT - ADVANCED', 'ADMINISTRATIVE ASSISTANT 2', 'ADMINISTRATIVE ASSISTANT IV', 'ADMINISTRATIVE SERVICES ASSOCIATE', 'ASSISTANT DIRECTOR OF ACADEMIC ADVISING', 'ASSISTANT FACILITIES MANAGER', 'ASSISTANT PROFESSOR OF MUSICOLOGY', 'ASSOCIATE CAPITAL PROJECT ANALYST', 'ASSOCIATE PROFESSOR OF HISTORY', 'AUTO CLAIMS ADJUSTER BODILY INJURY', 'CERTIFIED ANESTHESIOLOGIST ASSISTANT', 'CHIEF OF STAFF (DEPUTY DIRECTOR)', 'CITY PLANNING CONSULTANT (ASSOCIATE DIRECTOR)', 'DIRECTOR OF QUALITY AND SAFETY', 'DIRECTOR OF TRUST AND SAFETY', 'FRAUD AND PHYSICAL SECURITY SUPERVISOR', 'LEGISLATIVE AFFAIRS ASSOCIATE', 'MATHEMATICAL STATISTICIAN', 'SALES ADMINISTRATIVE ASSISTANT', 'SENIOR ASSOCIATE APPLICATION SPECIALIST', 'SENIOR PUBLIC RELATIONS & AFFAIRS SPECIALIST', 'SENIOR QUALITY CONTROL ASSOCIATE SCIENTIST', 'SENIOR REGULATORY AFFAIRS SPECIALIST', 'STUDENT INFORMATION SYSTEM SUPPORT SPECIALIST', 'SYSTEMS RELIABILITY AND SUPPORT SPECIALIST'], dtype=object), array(['ACADEMIC ADVISOR AND LECTURER', 'ACCOUNT MANAGER', 'ACCOUNT MANAGER/CLIENT RELATIONSHIPS', 'ACCOUNTANT - ADVANCED', 'ACCOUNTING & MARKETING EXEC', 'ACCOUNTING MANAGER', 'ACCOUNTS MANAGER', 'ACCOUNTS PAYABLE MANAGER', 'ADJUNCT REFERENCE LIBRARIAN', 'ADULT AND TEEN LIBRARIAN', 'ANALYTICS DATA ENGINEER', 'ASSISTANT BRANCH MANAGER', 'ASSISTANT MANAGER, HEALTH RECORDS', 'ASSISTANT PROPERTY MANAGER', 'AUTOMATION TEST ENGINEER 2', 'BSA/AML/ OFAC ADMINISTRATOR', 'CLINICAL OPERATIONS MANAGER', 'CLINICAL TRIAL MANAGER', 'COMMUNICATIONS & MARKETING MANAGER', 'COMMUNICATIONS ADMINISTRATOR', 'COMMUNICATIONS MANAGER', 'COMMUNITY ENGAGEMENT LIBRARIAN', 'COMPLIANCE AND SCHEDULE MANAGER', 'CONTENT MARKETING MANAGER', 'CONTRACT ENGAGEMENT MANAGER', 'DATABASE ADMINISTRATOR', 'DEPARTMENT MANAGER', 'DEPARTMENTAL ANALYST', 'DEPUTY ATTORNEY GENERAL', 'DEVELOPMENT ACCOUNTANT', 'DIGITAL COMMUNICATIONS MANAGER', 'DIGITAL MARKETING MANAGER', 'DISTRICT DATA MANAGER', 'FUNDRAISING DATA ANALYST', 'GRADUATE RESEARCH ASSISTANT', 'GRANTS & CONTENT MANAGER', 'HEALTH CARE ADVOCATE', 'HEALTH IT CONSULTANT', 'HEALTH PROGRAM ADMINISTRATOR 2', 'IMPLEMENTATION CONSULTANT', 'INFORMATION MANAGEMENT SPECIALIST', 'INTERNAL COMMUNICATION MANAGER', 'IT COMMUNICATIONS MANAGER', 'LEARNING AND PERFORMANCE CONSULTANT', 'LEARNING AND TEACHING ADMINISTRATOR', 'LIBRARIAN DEPARTMENT HEAD', 'LIBRARIAN, BRANCH MANAGER', 'LIBRARY CIRCULATION MANAGER', 'MAINTENANCE MANAGER', 'MANAGER OF POLICY AND ADVOCACY', 'MANAGER, ACCOUNTING & FINANCE', 'MANAGER, DOCUMENT CONTROL', 'METADATA LIBRARIAN', 'NATIONAL TRAINING MANAGER', 'PRETREATMENT MANAGER', 'PROCUREMENT AND CONTRACTS MANAGER', 'PROSPECT MANAGEMENT ANALYST', 'REFERENCE LIBRARIAN', 'RESEARCH ADMINISTRATOR SR', 'REVIEWER AND TEAM LEAD', 'SENIOR DATABASE ANALYST', 'SPECIAL EDUCATION/MATH TEACHER', 'SR. COMMUNICATIONS MANAGER', 'SR. CONTENT MARKETING MANAGER', 'SYSTEMS AND SUPPORT MANAGER', 'TEACHER/HEAD OF DEPARTMENT', 'TECHNICAL ACCOUNT MANAGER', 'TECHNICAL WRITING MANAGER', 'VIRTUAL CONTENT MANAGER', 'VP, PRODUCT MANAGEMENT'], dtype=object), array(['ACCOUNT EXECUTIVE', 'ADMINISTRATIVE COORDINATOR', 'ADMINISTRATIVE OFFICER', 'APPLICATIONS ENGINEER', 'BRANCH OPERATIONS SUPERVISOR', 'CEDENTIALING COORDINATOR', 'CHIEF DEVELOPMENT OFFICER', 'CHIEF FINANCIAL OFFICER', 'CHIEF NURSING INFORMATICS OFFICER', 'CHIEF PHILANTHROPY OFFICER', 'CLIENT EXPERIENCE COACH', 'COMMUNICATIONS EXECUTIVE', 'CONTENT EDITOR', 'CONTENT PRODUCER', 'CONTENT WRITER', 'CREATIVE CONTENT WRITER', 'CREATIVE DIRECTOR', 'CREDIT UNION MANAGER', 'DEPUTY EDITOR/GRAPHIC DESIGN', 'DIGITAL DESIGNER', 'DIRECTOR OF ANNUAL GIVING', 'DIRECTOR OF FINANCE', 'DIRECTOR OF FINANCE AND HR', 'DIRECTOR OF PLANNING', 'EXECUTIVE DIRECTOR', 'EXECUTIVE UNDERWRITER', 'FOREIGN SERVICE OFFICER', 'INDIRECT LOAN OFFICER', 'INSTRUCTION LIBRARIAN', 'INTERNAL MEDICINE-PCP', 'INVOICING ADMIN', 'LEARNING SUPPORT SUPERVISOR', 'LEASING ADMINISTRATOR', 'MANAGING DIRECTOR', 'MANAGING EDITOR', 'NURSE CLINICIAN', 'NURSE PRACTITIONER', 'PARK OPERATIONS SUPERVISOR', 'PAYROLL & INVOICING CLERK', 'PRACTICE ADMINISTRATOR', 'PRICIPAL PROFESSIONAL ENGINEER', 'PRINCIPAL NETWORK ENGINEER', 'PRINCIPAL PRODUCT MANAGER', 'PRINCIPAL QUALITY ENGINEER', 'PRINCIPAL RECRUITER', 'PROGRAM SPECIALIST SENIOR', 'RECREATION THERAPIST', 'REGIONAL ADMINISTRATOR', 'REGISTERED DIETITIAN', 'RESEARCH TECHNICIAN 2', 'SCIENCE INSTRUCTOR', 'SCIENCE TEACHER', 'SCIENCE TECHNICIAN', 'SCIENTIFIC PROGRAMMER', 'SENIOR ADMINISTRATOR', 'SENIOR APPLICATION PROGRAMMER', 'SENIOR DIGITAL MARKETING EXECUTIVE', 'SENIOR ENGINEERING SPECIALIST', 'SENIOR INSTRUCTOR', 'SENIOR LEARNING SPECIALIST', 'SENIOR MANAGING EDITOR', 'SENIOR OFFICER, FINANCE', 'SENIOR REPRESENTATIVE', 'SHIPPING/RECEIVING ADMIN', 'SITE RELIABILITY ENGINEER', 'SUPERVISION PRINCIPAL', 'TRANSITION REPRESENTATIVE', 'UPPER SCHOOL LIBRARIAN', 'WRITING CENTER DIRECTOR'], dtype=object), array(['"NICHE SOFTWARE" SPECIALIST', 'ACCOUNTING ASSOCIATE', 'ARCHIVES ASSOCIATE', 'ASSOCIATE CHEMIST', 'ASSOCIATE COPY CHIEF', 'ASSOCIATE GENERAL COUNSEL', 'ASSOCIATE IRB CHAIR', 'ASSOCIATE VICE PRESIDENT', 'BILLING COORDINATOR', 'BILLING SPECIALIST TEAM LEAD', 'BUSINESS APPLICATIONS ANALYST', 'CASH APPLICATION SPECIALIST', 'CHIEF ASSISTANT PUBLIC DEFENDER', 'CLIENT EXPERIENCE SPECIALIST', 'CLINICAL LABORATORY SCIENTIST', 'CLINICAL NEUROPSYCHOLOGIST', 'CLINICAL PHYSICIST', 'CLINICAL TECHNOLOGIST', 'CLINICAL THERAPIST', 'COMMUNICATION SPECIALIST', 'COMMUNICATIONS DIRECTOR', 'COMMUNICATIONS SPECIALIST', 'COMPLIANCE ASSOCIATE', 'COMPUTATIONAL SCIENTIST', 'CONTROLLING SPECIALIST', 'CREDENTIALING SPECIALIST', 'CUSTOMER SERVICE SPECIALIST', 'DEVELOPMENT ASSOCIATE', 'DIRECTOR OF COMMUNICATIONS', 'DIRECTOR, BUSINESS DEVELOPMENT', 'DISTILLERY SUPERVISOR', 'ECONOMIC DEVELOPMENT SPECIALIST', 'EPIDEMIOLOGIST', 'EPIDEMIOLOGIST II', 'HEAD OF ACCESSIBILITY', 'HIGH SCHOOL TEACHER', 'HR CLERICAL ASSISTANT', 'INSTRUCTIONAL TECHNOLOGIST', 'LEAD HR SPECIALIST', 'LEAN SIX SIGMA BLACKBELT', 'LEARNING SPECIALIST', 'LIBRARY ASSOCIATE', 'LIBRARY SPECIALIST', 'LOGISTICS COORDINATOR', 'LOGISTICS SUPERVISOR', 'MARKETING SPECIALIST', 'MEDICAL LABORATORY SCIENTIST', 'MICROBIAL/CHEMICAL TECHNOLOGIST', 'MICROBIOLOGIST', 'MIDDLE SCHOOL ENGLISH TEACHER', 'PERSONAL LOAN SPECIALIST', 'PHYSICAL SCIENTIST', 'PRINCIPAL SCIENTIST', 'PRINCIPLE DATA SCIENTIST', 'PROPOSAL SPECIALIST', 'PUBLIC SERVICE ADMINISTRATOR', 'RESEARCH SCIENTIST IV', 'RESEARCH TECHNOLOGIST', 'RESOURCE SOIL SCIENTIST', 'SCHOLARSHIP COUNSELOR', 'SENIOR COMMUNICATIONS SPECIALIST', 'SENIOR DEVELOPMENT ASSOCIATE', 'SENIOR GIS SPECIALIST', 'SENIOR RESEARCH SCIENTIST', 'SENIOR SUPERVISOR, DEVELOPMENT', 'SERVICE SPECIALIST', 'SPEECH LANGUAGE PATHOLOGIST', 'SPEECH-LANGUAGE PATHOLOGIST', 'SR. TECHNICAL SPECIALIST', 'STUDENT EMPLOYMENT SUPERVISOR', 'SYSTEM LEVEL CLINICAL NURSE SPECIALIST', 'SYSTEMS LIBRARIAN', 'TECHNICAL SPECIALIST', 'WEB ACCESSIBILITY EVALUATOR', 'WEB COMMUNICATIONS ADVISOR', 'YOUTH SERVICES LIBRARIAN'], dtype=object), array(['ASSOCIATE DIRECTOR OF ALUMNI AND DONOR RELATIONS', 'COMMUNITY ENGAGEMENT COORDINATOR', 'COMPLIANCE AND REGULATORY ADVOCACY COORDINATOR', 'CONSTRUCTION DOCUMENT CONTROL MANAGER', 'CONTACT TRACING DATA ADMINISTRATOR', 'DEVELOPMENT & COMMUNICATIONS COORDINATOR', 'DIRECTOR OF ADVANCEMENT COMMUNICATIONS', 'DIRECTOR OF CATALOGING & METADATA', 'DIRECTOR OF OPERATIONS AND MARKETING COMMUNICATIONS', 'DIRECTOR OF PURCHASING AND CONTRACTS', 'DIRECTOR, FINANCE AND ADMINISTRATION', 'IN HOUSE COUNSEL FOR A MAJOR NON-PROFIT', 'INFRASTRUCTURE ENGINEERING SENIOR MANAGER', 'LEAD NOISE AND VIBRATION PERFORMANCE ENGINEER', 'MANAGER OF DATA AND PROSPECT RESEARCH', 'PARTNER RELATIONSHIP AND MARKETING MANAGER', 'PAYROLL AND FINANCE ADMINISTRATOR', 'RECRUITMENT AND MARKETING COORDINATOR', 'SENIOR COORDINATOR, FUNDRAISING ANALYTICS', 'SENIOR MANAGER, PROGRAMMATIC ADVERTISING', 'SR DATA AND ANALYTICS PRODUCT MANAGER', 'STRATEGY & COMMUNICATIONS INTERN', 'TECHNOLOGY AND INNOVATION COORDINATOR'], dtype=object), array(['ACADEMIC ADVISOR', 'ADJUNCT', 'ADMINISTRATOR', 'AML INVESTIGATOR', 'ARCHIVIST', 'ART AIDE', 'ASSOCIATE DIRECTOR', 'ASSOCIATE EDITOR', 'ASTRONOMER', 'ATTORNEY', 'ATTORNEY III', 'AUDITOR', 'BARRISTER', 'BOOKKEEPER', 'BOOKSELLER', 'BRANCH CHIEF', 'BUSINESS MANAGER', 'BUYER', 'BUYER III', 'CEO', 'CHIEF OF STAFF', 'CLERK', 'CONTROLLER', 'COPYWRITER', 'CYBER SECURITY', 'DEBT ADVISOR', 'DEPUTY CHIEF COUNSEL', 'DIRECTOR', 'DJ', 'EDITOR', 'ESTIMATOR', 'GAME DESIGNER', 'GRANTS', 'GRAPHIC DESIGNER', 'GRAPHICS ARTIST', 'HR ADVISOR', 'HR GENERALIST', 'HR SPECIALIST', 'HUMAN RESOURCES', 'IN-HOUSE COUNSEL', 'INSIDE SALES', 'INSIDE SALES MANAGER', 'INTERNAL AUDITOR', 'IP SPECIALIST', 'IT EDP', 'IT SPECIALIST', 'IT SUPPORT SPECIALIST', 'LAB TECHNICIAN', 'LAW CLERK', 'LEAD GAME DESIGNER', 'LECTURER', 'LEGAL EDITOR', 'LEGAL SECRETARY', 'LIBRARIAN', 'LIFESTYLE DIRECTOR', 'MATH TEACHER', 'MEDICAL EDITOR', 'MEDICAL LIBRARIAN', 'MEDICAL SCRIBE', 'MEDICAL WRITER', 'MEMBER DATA SPECIALIST', 'MERCHANISER', 'MUSIC TEACHER', 'PARTNER', 'PHARMACIST', 'PHD STUDENT', 'PHILANTHROPY ASSOCIATE', 'PHYSICIAN', 'PHYSICIST', 'POLICY LEAD', 'PRODUCER', 'PRODUCT DESIGNER', 'PRODUCT OWNER', 'PSYCHOTHERAPIST', 'PURCHASING AGENT', 'R&D ASSOCIATE', 'RECRUITER', 'REPORTER', 'RESEARCH CHEMIST', 'RESEARCH DIRECTOR', 'RESEARCHER', 'RLA TEACHER', 'RN', 'SALES DIRECTOR', 'SALES REP', 'SECTION HEAD', 'SENIOR AUDITOR', 'SENIOR CHEMIST', 'SENIOR JOURNALIST', 'SOCIAL RESEARCHER', 'SOLUTIONS MANAGER', 'STAFF ATTORNEY', 'STAFF WRITER', 'SYSTEM ARCHITECT', 'TAXONOMIST', 'TEACHER', 'TEACHER/CAMPUS MINISTER', 'TECHNICAL DIRECTOR', 'TECHNICAL TRAINER', 'TECHNICAL WRITER', 'TECHNICIAN', 'TUTOR', 'UX DESIGNER', 'UX RESEARCHER', 'VICE PRESIDENT', 'WEALTH ADVISOR'], dtype=object), array(['1X1 COORDINATOR', 'ACADEMIC COORDINATOR', 'ART DIRECTOR', 'AUTONOMY ROBOTICS ENGINEER', 'CIRCULATION COORDINATOR', 'CITY COUNCIL COORDINATOR', 'COORDINATOR', 'CUSTODIAN OF RECORDS', 'DATA COORDINATOR', 'DEVELOPMENT COORDINATOR', 'DIRECTOR OF ACCOUNTING', 'DIRECTOR OF APPLICATIONS', 'DIRECTOR OF OPERATIONS', 'DIRECTOR OF SCHEDULING', 'DIRECTOR OF SUPPORT', 'EDITORIAL DIRECTOR', 'EDUCATION COORDINATOR', 'HR DIRECTOR', 'HR/BENEFITS COORDINATOR', 'INVENTORY ACCURACY COORDINATOR', 'JOB COORDINATOR', 'JOURNALS PRODUCTION COORDINATOR', 'LABORATORY GENETIC COUNSELOR', 'LIBRARY DIRECTOR', 'MARKETING DIRECTOR', 'MARKETING PRODUCER', 'MORTGAGE UNDERWRITER', 'OPERATIONS COORDINATOR', 'PAYROLL COORDINATOR', 'PRACTICE COORDINATOR', 'PRODUCTION EDITOR', 'PRODUCTION PROCESS LEAD', 'PROGRAM ADMINISTRATOR', 'PROGRAM COORDINATOR', 'PROGRAM DIRECTOR', 'PROJECT COORDINATOR', 'PROMOTION REVIEW EDITOR', 'PROPOSAL COORDINATOR', 'REFERRAL COORDINATOR', 'SALES CO-ORDINATOR', 'SEARCH COORDINATOR', 'SENIOR ART DIRECTOR', 'SENIOR COORDINATOR', 'SENIOR DIRECTOR OF IT', 'SENIOR DIRECTOR, ADVISOR', 'SENIOR POLICY ADVISOR', 'SENIOR WRITER/EDITOR', 'SERVICE COORDINATOR', 'SR. DIRECTOR', 'SUPPLY CHAIN COORDINATOR', 'VOLUNTEER COORDINATOR'], dtype=object), array(['BUSINESS COMPLIANCE MANAGER', 'BUSINESS DEVELOPMENT MANAGER', 'BUSINESS INITIATIVES MANAGER', 'BUSINESS INTELLIGENCE MANAGER', 'BUSINESS OPERATIONS MANAGER', 'BUSINESS PERFORMANCE ANALYST', 'BUSINESS SYSTEMS ANALYST', 'ENGINEERING ASSISTANT', 'ENTERPRISE SOLUTIONS ARCHITECT', 'FINANCIAL ASSISTANT', 'HEARING INSTRUMENT SPECIALIST', 'HUMAN RESOURCES ASSISTANT', 'HUMAN RESOURCES BUSINESS PARTNER', 'INFORMATION SECURITY ANALYST', 'INSTRUCTIONAL DESIGN MANAGER', 'INSTRUCTIONAL DESIGNER', 'LEARNING ENGAGEMENT ASSOCIATE', 'LEGAL ASSISTANT/JUNIOR EDITOR', 'MANAGER, STRATEGIC MESSAGING', 'MARKETING CONTENT SPECIALIST', 'NETWORK RELATIONS SPECIALIST', 'PRODUCT MARKETING SPECIALIST', 'QUALITY MANAGER/DESIGN ENGINEER', 'SENIOR ADMINISTRATIVE ANALYST', 'SENIOR CUSTOMER SUCCESS CONSULTANT', 'SENIOR FINANCIAL ANALYIST', 'SENIOR HUMAN RESOURCES ASSISTANT', 'SENIOR INSTITUTIONAL ANALYST', 'SENIOR LITIGATION PARALEGAL', 'SENIOR MANAGER, BUSINESS SOLUTIONS', 'SENIOR QUALITY ASSURANCE ENGINEER', 'SOFTWARE ENGINEERING MANAGER', 'TRAINING SERVICES CONSULTANT', 'TREASURY ACCOUNTING SPECIALIST'], dtype=object), array(['ASSOCIATE DIRECTOR CORPORATE INSURANCE', 'CUSTOMER SERVICE CALL CENTER SUPERVISOR', 'CUSTOMER SERVICE REP-UNLICENSED', 'CUSTOMER SERVICE REPRESENTATIVE', 'DIRECTOR OF DONOR STEWARDSHIP', 'DIRECTOR OF EVENTS & MARKETING', 'DIRECTOR OF EVENTS AND PROGRAMS', 'DIRECTOR OF HARDWARE ENGINEERING', 'DIRECTOR OF INSTITUTIONAL RESEARCH/REGISTRAR', 'DIRECTOR OF PROSPECT RESEARCH', 'DIRECTOR OF REHABILITATION SERVICES', 'DIRECTOR OF STUDENT SERVICES', 'DIRECTOR OF TECHNICAL SERVICES', 'DIRECTOR, DIRECT RESPONSE FUNDRAISING', 'EVENT SERVICES COORDINATOR', 'GEOSPATIAL SERVICE COORDINATOR', 'MANAGER OF INFORMATION SERVICES', 'MANAGER OF NEURODIAGNOSTICS', 'MOTION & GRAPHIC DESIGNER', 'POSTDOCTORAL RESEARCH ASSOCIATE', 'PRODUCT DESIGN SENIOR MANAGER', 'RESEARCH COORDINATOR - SENIOR', 'RESEARCH PROJECT DIRECTOR', 'SENIOR DIRECTOR, STRATEGY & OPERATIONS', 'SENIOR MOTION GRAPHICS DESIGNER', 'TECHNICAL SERVICES DIRECTOR'], dtype=object), array(['401(K) ANALYST', 'ACCOUNTANT', 'ACCOUNTANT (IN HOUSE)', 'ACCOUNTS PAYABLE', 'ACTUARIAL ANALYST', 'ANALYST', 'ANALYTICS MANAGER', 'BENEFITS ANALYST', 'BUSINESS ANALYST', 'COMMS CONSULTANT', 'COMPENSATION ANALYST', 'CONSULTANT', 'DATA ANALYST', 'DATA PRODUCT CONSULTANT', 'ENERGY POLICY ANALYST', 'FINANCIAL ANALYST', 'FISCAL ANALYST', 'FISHERY ANALYST', 'GEOBASE ANALYST', 'HUMAN RESOURCES ANALYST A', 'LABORATORY ANALYST', 'LEAD ANALYST', 'LEGAL TRANSLATOR', 'OPEN SOURCE ANALYST', 'ORACLE CLOUD CONSULTANT', 'PAYROLL ANALYST', 'PLANT PLANNER', 'PMO WIRELINE ANALYST', 'POLICY ANALYST', 'QA ANALYST', 'RELOCATION CONSULTANT', 'SENIOR ACCOUNTANT', 'SENIOR ANALYST', 'SENIOR COMPLIANCE ANALYST', 'SENIOR POLICY ANALYST', 'SENIOR POLICY PLANNER', 'SR. COMPENSATION ANALYST', 'SR. COMPLIANCE ANALYST', 'SR. PHARMACY CONSULTANT', 'STAFF ACCOUNTANT', 'SUPPLY CHAIN PLANNER', 'SYSTEMS ANALYST', 'TAX ACCOUNTANT', 'TUTOR/NANNY'], dtype=object), array(['CASE MANAGER - EMPLOYMENT SERVICES', 'CUSTOMER SERVICE', 'CUSTOMER SERVICE CLERK', 'CUSTOMER SUCCESS MANAGER', 'E-COMMERCE MANAGER', 'HR BUSINESS PARTNER', 'HUMAN RESOURCES DIRECTOR', 'HUMAN RESOURCES MANAGER', 'HUMAN RESOURCES SPECIALIST', 'JR. RESEARCH ASSOCIATE', 'LIBRARY ACCESS SERVICES MANAGER', 'MARKET RESEARCH PROJECT MANAGER', 'MRO BUSINESS OWNER', 'PRESS SECRETARY', 'PROSPECT RESEARCH ANALYST', 'RECORDS MANAGEMENT CLERK 1', 'RECRUITER IN HOUSE', 'REIMBURSEMENT DIRECTOR', 'RESEARCH ASSOCIATE', 'RESEARCH ASSOCIATE 1', 'RESEARCH MANAGER', 'REVENUE CYCLE MANAGER', 'SENIOR MANAGER, RESOURCE STRATEGY', 'SENIOR RECRUITER', 'SENIOR RESEARCH ANALYST', 'SENIOR RESEARCH ASSOCIATE', 'SENIOR RESOURCE ANALYST', 'SR DIRECTOR, PRESALES', 'SR. SCRUM MASTER', 'UX RESEARCH MANAGER'], dtype=object), array(['ADVOCATE MANAGER', 'ASSET MANAGER', 'BRAND MANAGER', 'CASE MANAGER', 'CASE MANAGER/PARALEGAL', 'CORPORATE ATTORNEY', 'DATA ENGINEER', 'DATA MANAGER', 'DATA REVIEWER', 'DEPARTMENT HEAD', 'DEVELOPMENT MANAGER', 'DIRECTOR LOYALTY MARKETING', 'EMPLOYABILITY MANAGER', 'ENROLLMENT MANAGER', 'EVENT MANAGER', 'EVENTS MANAGER', 'EXPO MANAGER', 'FINANCE MANAGER', 'FIRM MANAGER', 'FUNDING MANAGER', 'GENERAL MANAGER', 'GRANT OFFICER', 'GRANTS MANAGER', 'HEAD GARDENER', 'HR MANAGER', 'IT MANAGER', 'IT PROJECT MANAGER', 'LAWYER (PARTNER)', 'LEAD PROGRAM ARCHITECT', 'LEAD UNDERWRITER', 'MANAGER', 'MANAGER, STRATEGY', 'MARKETING MANAGER', 'MARKETING VP', 'OFFICE MANAGER', 'OPERATIONS MANAGER', 'PARALEGAL', 'PARTNER MANAGER', 'PATENT EXAMINER', 'PAYROLL MANAGER', 'PLANT BREEDER', 'PRACTICE MANAGER', 'PRODUCT MANAGER', 'PRODUCT SUPPORT MANAGER', 'PRODUCTION MANAGER', 'PROGRAM ANALYST', 'PROGRAM ANALYST I', 'PROGRAMMER', 'PROGRAMMER ANALYST 2', 'PROGRAMMER ANALYST 3', 'PROJECT MANAGER', 'PROJECT SUPPORT ANALYST', 'PROPERTY ACCOUNTANT', 'PROPERTY MANAGER', 'PROPOSAL MANAGER', 'PUBLIC ART MANAGER', 'RECORDS PROJECT MANAGER', 'REVENUE ANALYST', 'REVENUE MANAGER', 'SENIOR MANAGER', 'SENIOR PARTNER', 'SENIOR PLANNER', 'SOFTWARE SUPPORT MANAGER', 'SR PRODUCT MANAGER', 'SR. PRODUCT MANAGER', 'SR. PROJECT MANAGER', 'STAFF PARALEGAL', 'STORE MANAGER', 'TAX SENIOR MANAGER', 'TEAM LEADER', 'TRADEMARK PARALEGAL', 'TRAINING MANAGER', 'VP OF MARKETING', 'VP, EVENTS MANAGER', 'WORKDAY PROJECT MANAGER'], dtype=object), array(['ANALOG ENGINEER', 'AUTOMATION ENGINEER', 'BIOMEDICAL ENGINEER', 'CHIEF ENGINEER', 'CIVIL ENGINEER', 'CONTENT DESIGNER', 'CRIME SCENE INVESTIGATOR', 'CYBER DEFENCE ENGINEER', 'CYBERSECURITY ENGINEER', 'DESIGN ENGINEER', 'ELECTRICAL ENGINEER', 'ELECTRONICS ENGINEER', 'ELECTRONICS ENGINEER SENIOR', 'ENGINEER II', 'ENGINEERING MANAGER', 'ENGINEERING PSYCHOLOGIST', 'ENGLISH TEACHER (YEAR 16)', 'ENVIRONMENTAL ENGINEER', 'HEAD OF ENGINEERING', 'HELP DESK REPRESENTATIVE', 'INTEGRITY ENGINEER', 'IT HELPDESK ENGINEER', 'JUNIOR CIVIL ENGINEER', 'JUNIOR SOFTWARE ENGINEER', 'LEAD PROCESS ENGINEER', 'LEAD SERVICE DESIGNER', 'MANAGER, ENGINERING', 'MECHANICAL ENGINEER', 'PROFESSIONAL ENGINEER', 'REGISTERED CLINICAL NURSE', 'SENIOR CREATIVE DESIGNER', 'SENIOR DATA ENGINEER', 'SENIOR HEALTH RESEARCHER', 'SENIOR SOFTWARE ENGINEER', 'SENIOR SYSTEMS ENGINEER', 'SERVICE DESIGNER', 'SIGNAL ENGINEER', 'SOFTWARE ENGINEER', 'SOFTWARE ENGINEER I', 'SOLUTION ENGINEER', 'SR SOFTWARE ENGINEER', 'SYSTEM ENGINEER', 'SYSTEMS ENGINEER', 'TEST ENGINEER', 'VOLUNTEER SCREENING MANAGER', 'VP OF ENGINEERING'], dtype=object), array(['ASSISTANT PROVOST; DIRECTOR, CENTER FOR FACULTY EXCELLENCE', 'CONTENT STRATEGIST/CONTENT DESIGNER', 'DEPUTY DIRECTOR, EVENTS & ATTENDEE EXPERIENCE', 'DIRECTOR, ENGAGEMENT & STRATEGIC INITIATIVES', 'EXECUTIVE DIRECTOR STRATEGIC INITIATIVES', 'SENIOR BUSINESS INTELLIGENCE DEVELOPER', 'SENIOR ENGINEER SPECIALIST - NETWORK OPERATIONS', 'SENIOR VICE PRESIDENT & ASSOCIATE GENERAL COUNSEL', 'SOFTWARE DEVELOPMENT ENGINEER IN TEST'], dtype=object), array(['PREDOCTORAL CURRICULUM COORDINATOR AND PROGRAM ADMINISTRATOR, MMSC IN DENTAL EDUCATION'], dtype=object), array(["EXECUTIVE VICE PRESIDENT/MARKET RESEARCH, GENERAL MANAGER (OF A RESEARCH FIRM THAT'S A WHOLLY-OWNED SUBSIDIARY OF MY LARGER COMPANY)"], dtype=object), array(['ACCOUNTS ASSISTANT', 'ADMIN ASSISTANT', 'ASSISSTANT DIRECTOR', 'ASSISTANT CONTROLLER', 'ASSISTANT COORDINATOR', 'ASSISTANT DIRECTOR', 'ASSISTANT DIRECTOR, OPERATIONS', 'ASSISTANT PAC COORDINATOR', 'ASSISTANT PROFESSOR', 'ASSOCIATE', 'ASSOCIATE ATTORNEY', 'ASSOCIATE PROFESSOR', 'ASSOCIATE PROVOST', 'ASSOCIATE SCIENTIST 1', 'CONTENT SPECIALIST', 'CONTENT STRATEGIST', 'CURATORIAL ASSISTANT', 'DATA SCIENTIST', 'EXECUTIVE ASSISTANT', 'INSIGHTS ANALYST', 'LAB ASSISTANT', 'LEGAL ASSISTANT', 'LOAN OFFICER ASSISTANT', 'OPERATIONS ASSOCIATE', 'POSTGRADUATE ASSOCIATE', 'PROGRAM ASSISTANT', 'PROGRAM ASSOCIATE', 'PROJECT ASSISTANT', 'RESEARCH ASSISTANT', 'SALES ASSOCIATE', 'SALESFORCE CONSULTANT', 'SCIENTIST I', 'SENIOR ASSOCIATE', 'SENIOR ASSOCIATE CONSULTANT', 'SENIOR DATA SCIENTIST', 'SENIOR SCIENTIST', 'SENIOR SCIENTIST I', 'SENIOR STATISTICAL OFFICER', 'SR. CONTENT SPECIALIST', 'SR. SCIENTIST', 'STAFF ASSOCIATE', 'STAFF SCIENTIST', 'STATISTICIAN', 'SYSTEMS ADMINISTRATOR', 'TEACHING ASSISTANT', 'UTILITIES ANALYST'], dtype=object), array(['ACADEMIC PROGRAM MANAGER', 'ADVISOR & PROGRAM MANAGER', 'BROKER RELATIONSHIP MANAGER', 'GRANTS & COMPLIANCE MANAGER', 'GROUP MANAGER PROJECT MANAGEMENT', 'INFORMATION AND PROGRAM MANAGER', 'MANAGEMENT AND PROGRAM ANALYST', 'OPERATIONS & MARKETING MANAGER', 'PARTNER MARKETING MANAGER', 'PROGRAM MANAGER', 'PROGRAMME MANAGEMENT OFFICE MANAGER', 'PROGRAMMER TEAM LEAD', 'PROJECT/PROGRAM MANAGER', 'REGIONAL SALES MANAGER', 'SENIOR MARKETING MANAGER', 'SENIOR PROGRAM MANAGER', 'SOFTWARE PROGRAM MANAGER', 'SR PROGRAM MANAGER', 'STORE GENERAL MANAGER', 'TELEHEALTH PROGRAM MANAGER', 'VALET OPERATIONS MANAGER', 'WHOLESALE OPERATIONS MANAGER', 'YOUTH AND FAMILY PROGRAMS MANAGER'], dtype=object), array(['CLIENT PLAFORM ENGINEER/TIER 3 SUPPORT', 'DIRECTOR OF ALUMNI ENGAGEMENT', 'DIRECTOR OF DEVELOPMENT OPERATIONS', 'DIRECTOR OF ENROLLMENT MANAGEMENT', 'DIRECTOR OF MULTIFAMILY HOUSING DEVELOPMENT', 'DIRECTOR OF PROGRAM DEVELOPMENT', 'DIRECTOR, PEOPLE OPERATIONS', 'DIRECTOR, RESOURCE DEVELOPMENT', 'LEARNING & DEVELOPMENT FACILITATOR', 'LEARNING & DEVELOPMENT MANAGER', 'LEARNING AND DEVELOPMENT LEAD', 'MANAGER NEW PRODUCT DEVELOPMENT', 'PEOPLE DEVELOPMENT PARTNER', 'PEOPLE OPERATIONS MANAGER', 'PROJECT COORDINATOR, MATERIALS DEVELOPMENT', 'PROJECT MANAGER, ENERGY IMPLEMENTATION', 'RECRUITMENT & RETENTION SPECIALIST', 'SENIOR APPIAN DEVELOPER', 'SENIOR DEVELOPMENT PROJECT MANAGER'], dtype=object)] ```Looking at the clusters, the K-Means does anecdotally look to cluster the job titles slightly better.
OPTICS Fourth Test
Instead of defining clusters by the total number of clusters the results should have, instead OPTICS uses the minimum number of samples in one cluster. Unfortunately, there is the possibility for the cluster to be undefined, or -1.
from sklearn.cluster import OPTICS
op_model = OPTICS(min_samples = 5).fit(test_df2.toarray())
aam_cluster2 = aam_cluster2.assign(cluster3 = op_model.labels_)
cluster_list = []
for i in range(max(aam_cluster2['cluster3'])):
exec("cluster_%d = []" % (i))
exec("cluster_%d = np.unique(aam_cluster2[aam_cluster2['cluster3'] == %d]['job_title'])" % (i,i))
exec("cluster_list.append(cluster_%d)" % (i))
print(cluster_list)
print('Unlabeled:', sum(op_model.labels_ == -1) / len(op_model.labels_)*100,'%')
Expand
``` [array(['ASSOCIATE VICE PRESIDENT', 'CRIME SCENE INVESTIGATOR', 'CUSTOMER SERVICE SPECIALIST', 'HUMAN RESOURCES SPECIALIST', 'RESEARCH SCIENTIST IV', 'SENIOR RESEARCH SCIENTIST', 'SERVICE SPECIALIST'], dtype=object), array(['ARCHIVIST', 'GRAPHICS ARTIST', 'HR SPECIALIST', 'IP SPECIALIST', 'IT SPECIALIST', 'LEAD HR SPECIALIST', 'PHARMACIST', 'PHYSICAL SCIENTIST', 'PHYSICIAN', 'PHYSICIST', 'SCIENTIST I'], dtype=object), array(['COPYWRITER', 'DIRECTOR', 'EDITOR', 'HR DIRECTOR', 'PRODUCER'], dtype=object), array(['IT PROJECT MANAGER', 'PRODUCT MANAGER', 'PRODUCTION MANAGER', 'PROJECT MANAGER', 'SR PRODUCT MANAGER', 'SR. PRODUCT MANAGER', 'SR. PROJECT MANAGER'], dtype=object), array(['PARALEGAL', 'PAYROLL MANAGER', 'PROGRAM ANALYST', 'PROGRAM ANALYST I', 'PROGRAMMER ANALYST 2', 'PROGRAMMER ANALYST 3', 'SENIOR PROGRAM MANAGER', 'SOFTWARE PROGRAM MANAGER', 'SR PROGRAM MANAGER'], dtype=object), array(['DIRECTOR OF OPERATIONS', 'OPERATIONS COORDINATOR', 'PRACTICE COORDINATOR', 'SEARCH COORDINATOR', 'SENIOR COORDINATOR', 'SERVICE COORDINATOR'], dtype=object), array(['CONTENT MARKETING MANAGER', 'CONTRACT ENGAGEMENT MANAGER', 'GRANTS & CONTENT MANAGER', 'SR. CONTENT MARKETING MANAGER', 'VIRTUAL CONTENT MANAGER'], dtype=object)] Unlabeled: 93.08176100628931 % ```As we can see, the percent unlabeled data is quite large.
Full Clustering
We can now cluster with the full data. As there are 13,114 unique job titles, will try to create around 2,000 clusters in order to reduce the uniqueness by over 80%.
# this takes a very long time
aam_cluster_final = aam
aam_cluster_final = aam_cluster_final[['job_title','age_group_o','exp_group_o','exp_field_group_o',
'education_o','total_gross_salary']]
aam_cluster_final = aam_cluster_final.groupby(['job_title'], as_index=False).median()
aam_transform = second_pipeline.fit_transform(aam_cluster_final)
cluster_model = KMeans(n_clusters=2000).fit(aam_transform)
pickle.dump(cluster_model, open('kmeans_final_model.sav', 'wb')) #save model?
aam_cluster_final = aam_cluster_final.assign(cluster = cluster_model.labels_)
aam_cluster_final.to_csv('aam_usd_cluster.csv', index=False, encoding='utf-8')
[Pipeline] ...... (step 1 of 1) Processing preprocessor, total= 0.1s
cluster_list = []
for i in range(max(aam_cluster_final['cluster'])):
exec("cluster_%d = []" % (i))
exec("cluster_%d = np.unique(aam_cluster_final[aam_cluster_final['cluster'] == %d]['job_title'])" % (i,i))
exec("cluster_list.append(cluster_%d)" % (i))
# Checking for Duplicates
overlap = []
for i in range(len(cluster_list)-1):
for j in range(i+1,len(cluster_list)-i):
if len(set(cluster_list[i]) & set(cluster_list[j])) > 1:
overlap.append([i,j,set(cluster_list[i]) & set(cluster_list[j])])
overlap
# cluster_list
[]
For fun, we can also run the OPTICS model and view the results.
# takes even longer
aam_cluster_final = aam
aam_cluster_final = aam_cluster_final[['job_title','age_group_o','exp_group_o','exp_field_group_o',
'education_o','total_gross_salary']]
aam_cluster_final = aam_cluster_final.groupby(['job_title'], as_index=False).median()
aam_transform = second_pipeline.fit_transform(aam_cluster_final)
cluster_model = OPTICS(min_samples = 3).fit(aam_transform.toarray())
pickle.dump(cluster_model, open('optics_final_model.sav', 'wb')) #save model?
aam_cluster_final = aam_cluster_final.assign(cluster2 = cluster_model.labels_)
aam_cluster_final.to_csv('aam_usd_cluster_optics.csv', index=False, encoding='utf-8')
cluster_list = []
for i in range(max(aam_cluster_final['cluster2'])):
exec("cluster_%d = []" % (i))
exec("cluster_%d = np.unique(aam_cluster_final[aam_cluster_final['cluster2'] == %d]['job_title'])" % (i,i))
exec("cluster_list.append(cluster_%d)" % (i))
# Checking for Duplicates
overlap = []
for i in range(len(cluster_list)-1):
for j in range(i+1,len(cluster_list)-i):
if len(set(cluster_list[i]) & set(cluster_list[j])) > 1:
overlap.append([i,j,set(cluster_list[i]) & set(cluster_list[j])])
overlap
max(aam_cluster_final['cluster2'])
544
Exploring Clusters
Now that the above models have run, we can assess the clusters.
# Preprocessing Skip
aam = pd.read_csv('aam_clean.csv')
aam_cluster = pd.read_csv('aam_usd_cluster.csv')
aam_cluster = aam_cluster.astype({'cluster':'string'})
# Join with Cluster Association
aam = aam.merge(aam_cluster[['job_title','cluster']], how='left', on=['job_title'])
print('Missing Job Title Clusters:',len(aam[aam['cluster'].isna()]))
Missing Job Title Clusters: 0
K-Means Cluster Results
Looking at the K-Means results, there are a small amount of clusters with only one memeber, which is not ideal, but better than using the job title column as is.
# K-Means Cluster
cluster_counts = aam_cluster[['job_title','cluster']].groupby(['cluster'], as_index=False).count()
print("Clusters With Only 1 Member:", len(cluster_counts[cluster_counts['job_title']==1]))
Clusters With Only 1 Member: 303
OPTICS Cluster
Looking at the Optics Cluster, there are 1/3 the number of clusters compared to the K-Means cluster, but over 80% of the data is unlabeled, which is not ideal.
# OPTICS
aam_cluster2 = pd.read_csv('aam_usd_cluster_optics.csv')
# aam_cluster2 = aam_cluster2.astype({'cluster2':'string'})
cluster_counts = aam_cluster2[['job_title','cluster2']].groupby(['cluster2'], as_index=False).count()
print("Total Clusters:", max(cluster_counts['cluster2']))
print("Unlabeled Rows:", len(aam_cluster2[aam_cluster2['cluster2'] == -1]) / len(aam_cluster2)*100,'%')
Total Clusters: 544
Unlabeled Rows: 82.21916971916971 %
Exploring a Random Subset
We can generate a random subset of 10 K-Means clusters to look at, and compare the first job title to what the OPTICS cluster classified it as.
random.seed(30)
k_means_rand = random.choices(np.unique(aam_cluster['cluster']), k=10)
optics_list = []
print('K-Means Clusters:')
for i in k_means_rand:
print('Cluster:',i, np.unique(aam_cluster[aam_cluster['cluster'] == i]['job_title']))
optics_list.append(np.unique(aam_cluster[aam_cluster['cluster'] == i]['job_title'])[0])
print('')
print('OPTICS Clusters:')
for j in optics_list:
o_c = int(aam_cluster2[aam_cluster2['job_title'] == j]['cluster2'])
if o_c != -1:
print('Cluster:',o_c, np.unique(aam_cluster2[aam_cluster2['cluster2'] == o_c]['job_title']))
K-Means Clusters:
Cluster: 1969 ['COORDINATOR CORPORATE OFFICE AND FACILITY SERVICES']
Cluster: 1518 ['ASSISTANT LIBRARY DIRECTOR' 'LIBRARY ASSISTANT DIRECTOR'
'LIBRARY ASSISTANT SUPERVISOR' 'LIBRARY SYSTEM ADMINSITRATOR'
'SENIOR LIBRARY ASSISTANT' 'SYSTEMS AND DISCOVERY LIBRARIAN']
Cluster: 1051 ['MANAGER DEI CORPORATE PARTNERSHIPS' 'PRE-AWARD RESEARCH ADMINISTRATOR'
'PRINCIPAL ENTERPRISE PROJECT MANAGER'
'RECREATION SPORTS PROGRAM MANAGER'
'SENIOR CORPORATE PHILANTHROPY MANAGER']
Cluster: 375 ['HIMAN RESOURCES BUSINESS PARTNER' 'HUMAN RESOURCES BUISNESS PARTNER'
'HUMAN RESOURCES BUSINESS PARTNER'
'HUMAN RESOURCES BUSINESS PARTNER (HRBP)'
'HUMAN RESOURCES SUCCESS PARTNER' 'RESPONSABLE DES RESSOURCES HUMAINES'
'SENIOR HUMAN RESOURCES BUSINESS PARTNER'
'SENIOR QUALITY ASSURANCE SUPERVISOR'
'STAFF HUMAN RESOURCES BUSINESS PARTNER']
Cluster: 1376 ['DEPARTMENT CHAIR AND TEACHER' 'TEACHER AND DEPARTMENT CHAIR'
'TEACHER/HEAD OF DEPARTMENT']
Cluster: 1460 ['CHIEF ACADEMIC OFFICER' 'CHIEF COMPLIANCE OFFICER'
'COMMERCIAL LOAN OFFICER' 'COMMERCIAL OFFICER' 'COMPLIANCE OFFICER'
'SENIOR CLERICAL OFFICER' 'SR. COMPLIANCE OFFICER'
'TAX COMPLIANCE OFFICER' 'VP - COMPLIANCE OFFICER']
Cluster: 1712 ['DIVERSITY, EQUITY AND INCLUSION DIRECTOR'
'HEAD OF DIVERSITY, EQUITY, AND INCLUSION']
Cluster: 353 ['CIVIL ENGINEER' 'CIVIL ENGINEER II' 'ENGINEER III'
'JUNIOR CIVIL ENGINEER' 'LIVE IN CAREGIVER' 'NUCLEAR ENGINEER II'
'SENIOR CIVIL ENGINEER']
Cluster: 979 ['ASSURANCE SENIOR MANAGER' 'BUSINESS PERFORMANCE MANAGER'
'NATURAL RESOURCES MANAGER' 'PARTNER SUCCESS MANAGER'
'SALES MANAGER GROUP INSURANCE']
Cluster: 1829 ['REAL ESTATE STRATEGIST' 'REGISTERED MASSAGE THERAPISTS (RMT)'
'SR. CONTRACTS REPRESENTATIVE' 'STATE INVESTIGATIVE REPORTER'
'TREATMENT SERVICES THERAPIST']
OPTICS Clusters:
Cluster: 362 ['HIMAN RESOURCES BUSINESS PARTNER' 'HUMAN RESOURCES BUISNESS PARTNER'
'HUMAN RESOURCES BUSINESS PARTNER']
Cluster: 544 ['DIRECTOR OF EQUITY, DIVERSITY & INCLUSION'
'DIVERSITY, EQUITY AND INCLUSION DIRECTOR'
'HEAD OF DIVERSITY, EQUITY, AND INCLUSION']
The K-Means clusters look fairly similar, but still aren’t grouping as well as they could be. The first result of each cluster seemed to be mostly undefined in the OPTICS cluster, which is unfortunate as the OPTICS Clusters, when found, do look better than the K-Means clusters. As such, we will continue with the complete, but imperfect K-Means cluster.
Data Exploration and Analysis
There are a large number of questions that could be answered with this dataset. In each of the following sections, we will focus on plots and analysis on the most relevant features in each (data grouping/filtering) and will try not to overlap analysis unless specific cross comparisons are being done.
All Data
Responses by Country
As we can see from the following plot, most responses are from the United States, with a smaller number of repsponses from Canada, the UK, and Germany.
df = aam[['form_timestamp','country']].groupby(['country'], as_index=False).count()
df.loc[df['form_timestamp'] <= 50, 'country'] = 'OTHER'
df = df.groupby(['country'], as_index=False).sum()
fig = px.pie(df, names='country', values='form_timestamp',
title='Breakdown by Country', labels={'country':'Country', 'form_timestamp':'Responses'})
fig.update_traces(textposition='inside', textinfo='percent+label')
# fig.show()
fig.write_image("fig1.png")
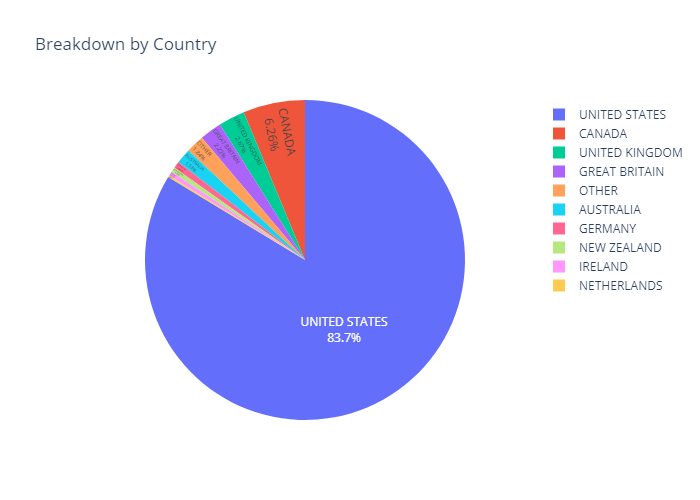
Responses by Currency
Breaking the responses down by currency, most responses are in USD, with CAD and GBP taking up a smaller portion of responses.
aam['currency'] = aam['currency'].apply(lambda x: x.upper())
df = aam[['form_timestamp','currency']].groupby(['currency'], as_index=False).count()
df.loc[df['form_timestamp'] <= 50, 'currency'] = 'OTHER'
df = df.groupby(['currency'], as_index=False).sum()
fig = px.pie(df, names='currency', values='form_timestamp',
title='Breakdown by Currency', labels={'currency':'Currency', 'form_timestamp':'Responses'})
fig.update_traces(textposition='inside', textinfo='percent+label')
# fig.show()
fig.write_image("fig2.png")
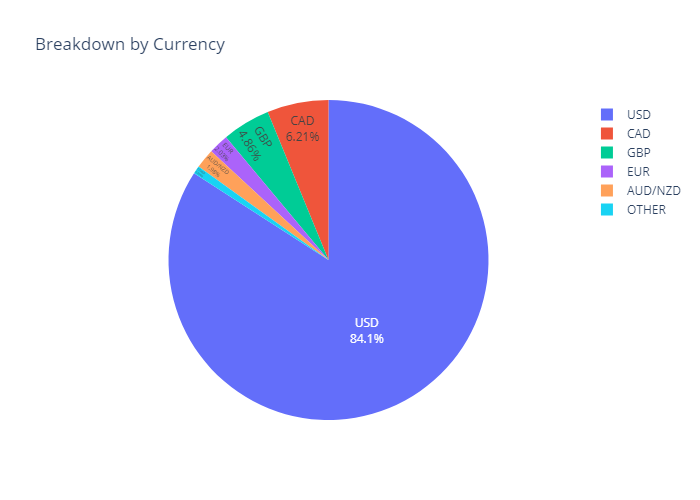
USD Only
Adding currency conversion, especially for previous time periods (in this case 2022) is out of scope for this specific project. As such, for the remaining analysis and modeling, we will be focusing on only data reported in USD.
aam_usd = aam[aam['currency'] == 'USD']
Breakdown by Industry
Unlike Country and Currency, Industry seems to be fairly evenly distributed, with higher responses from Higher Education and Computing/Tech.
df = aam_usd[['form_timestamp','industry']].groupby(['industry'], as_index=False).count()
df.loc[df['form_timestamp'] <= 500, 'industry'] = 'OTHER'
df = df.groupby(['industry'], as_index=False).sum()
fig = px.pie(df, names='industry', values='form_timestamp',
title='Breakdown by Industry', labels={'industry':'Industry', 'form_timestamp':'Responses'})
fig.update_traces(textposition='inside', textinfo='percent+label')
# fig.show()
fig.write_image("fig3.png")

Breakdown by Functional Area
If we break down by Functional Area, Computing/Tech still has a higher response percent compariatively, but the second highest category (other than Other) is Accounting, Banking, and Finance.
df = aam_usd[['form_timestamp','functional_area']].groupby(['functional_area'], as_index=False).count()
df.loc[df['form_timestamp'] <= 500, 'functional_area'] = 'OTHER'
df = df.groupby(['functional_area'], as_index=False).sum()
fig = px.pie(df, names='functional_area', values='form_timestamp',
title='Breakdown by Functional Area', labels={'functional_area':'Functional Area', 'form_timestamp':'Responses'})
fig.update_traces(textposition='inside', textinfo='percent+label')
# fig.show()
fig.write_image("fig4.png")
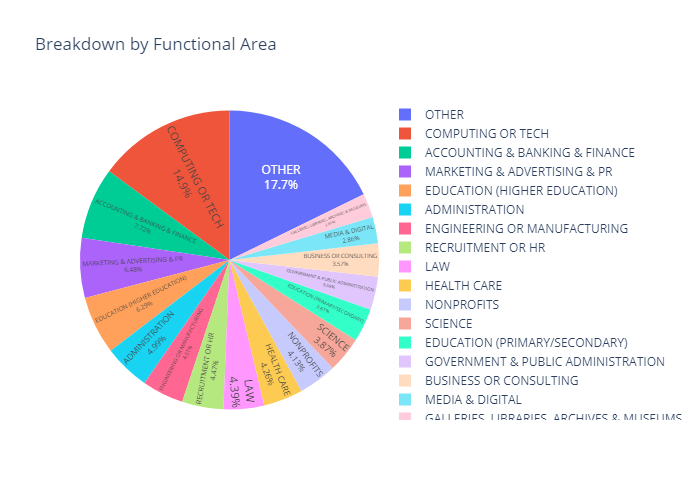
Total Salary in 2022 vs. 2023
Looking at the distribution of Total Salary in 2022 vs. 2023 (capping at $600,000 per year), both years look to have very similar distributions, but the median Total Salary for 2023 is slightly higher ($85,000 vs. $90,500).
df = aam_usd[(aam_usd['total_gross_salary'] <= 600000)]
fig = px.violin(df, x='year',y='total_gross_salary', points='outliers', title='Box Plot of Total Salary by Year',
color='year', box=True, labels={'year':'Year','total_gross_salary':'Total Salary'})
# fig.show()
fig.write_image("fig5.png")
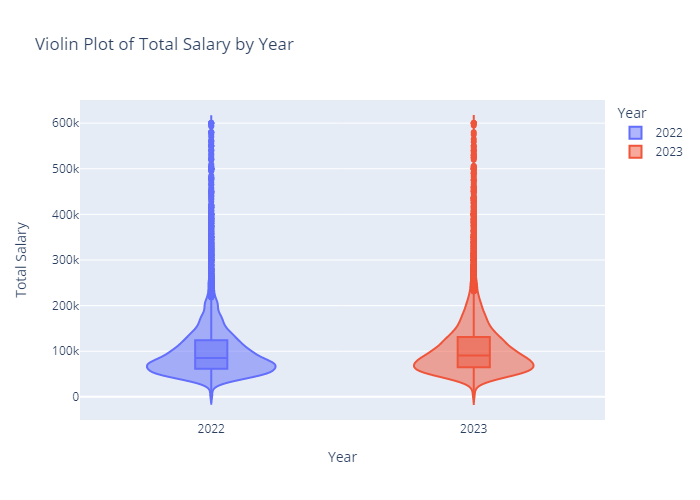
df = aam_usd[(aam_usd['total_gross_salary'] <= 600000)]
print('2022 Quantiles:')
print('Q3: $%.2f' %(df[df['year'] == 2022]['total_gross_salary'].quantile([0.75])))
print('Median: $%.2f' %(df[df['year'] == 2022]['total_gross_salary'].quantile([0.5])))
print('Q1: $%.2f' %(df[df['year'] == 2022]['total_gross_salary'].quantile([0.25])))
print('')
print('2023 Quantiles:')
print('Q3: $%.2f' %(df[df['year'] == 2023]['total_gross_salary'].quantile([0.75])))
print('Median: $%.2f' %(df[df['year'] == 2023]['total_gross_salary'].quantile([0.5])))
print('Q1: $%.2f' %(df[df['year'] == 2023]['total_gross_salary'].quantile([0.25])))
2022 Quantiles:
Q3: $124000.00
Median: $85000.00
Q1: $61500.00
2023 Quantiles:
Q3: $131390.50
Median: $90500.00
Q1: $65000.00
Industry Average Total Salary in 2022 vs. 2023
Looking at the individual Industries, for the most part, Average Total Salaries have increased from 2022 to 2023.
df = aam_usd[(aam_usd['total_gross_salary'] >= 0)]
df = df.astype({'year':'string'})
fig = px.histogram(df, x='year',y='total_gross_salary', title='Industry Average Total Salary in 2022 vs. 2023',
color='year', labels={'industry':'Industry','total_gross_salary':'Total Salary', 'year':'Year'},
histfunc='avg', animation_frame='industry', animation_group='industry', range_y = [0,200000])
# fig.show()
fig.write_html('fig6.html')
HTML Figure Located Elsewhere
Functional Area Average Total Salary in 2022 vs. 2023
Looking at the individual Industries, for the most part, Average Total Salaries have increased from 2022 to 2023.
df = aam_usd[(aam_usd['total_gross_salary'] >= 0)]
df = df.astype({'year':'string'})
fig = px.histogram(df, x='year',y='total_gross_salary', title='Functional Area Average Gross Salary in 2022 vs. 2023',
color='year', labels={'functional_area':'Functional Area','total_gross_salary':'Total Salary', 'year':'Year'},
histfunc='avg', animation_frame='functional_area', animation_group='functional_area', range_y = [0,200000])
# fig.show()
fig.write_html('fig7.html')
HTML Figure Located Elsewhere
Statistical Tests for Difference in Total Salary
We can use the Student’s t-test to test if the average salary in 2023 was significantly different than the average salary in 2022 for salaries reported in USD. We are able to use the independent sample assumption because the survey results came from two separate surveys.
df = aam_usd[(aam_usd['total_gross_salary'] <= 600000)]
fig = px.histogram(df, x='total_gross_salary', title='Total Salary Distribution', color='year',
labels={'total_gross_salary':'Total Salary', 'year':'Year'})
# fig.show()
fig.write_image("fig8.png")
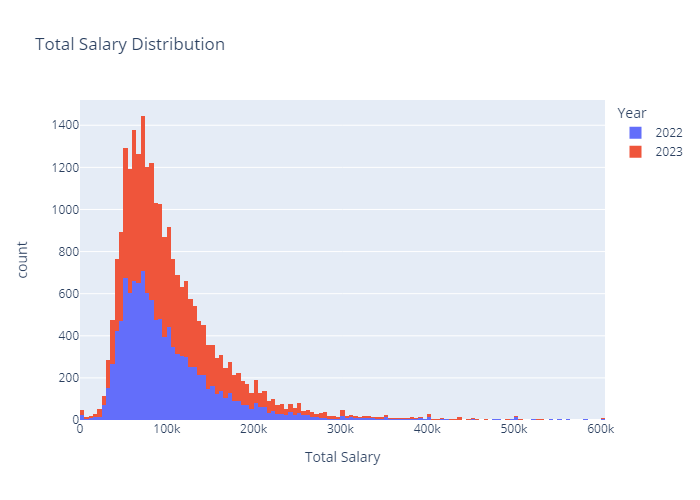
From the above histogram, the distribution of Total Salaries is log normal (non-negative), especially when taking into account outliers over $600,000 a year. We will conduct the test on salary under $600,000 so that extremely high salaries do not skew the results.
# Log Normal Fit
df = aam_usd[(aam_usd['total_gross_salary'] <= 600000)]
s, loc, scale = stats.lognorm.fit(df['total_gross_salary'], floc=0)
z_x = list(range(0,600000,100))
z = stats.lognorm.pdf(z_x, s, scale=scale)
plt.hist(df['total_gross_salary'], bins = 100, density=True, alpha=0.75)
plt.plot(z_x, z)
plt.savefig('fig16.png')
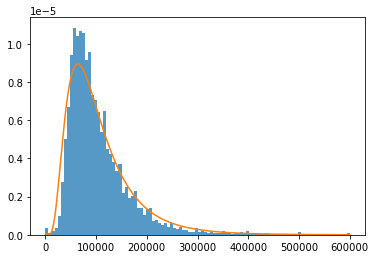
print('Scale:',scale)
print('Shape',s)
Scale: 90234.86852584557
Shape 0.5873330514134909
# Student's t-test
df = aam_usd[(aam_usd['total_gross_salary'] <= 600000)]
salaries_23 = df[df['year'] == 2023]['total_gross_salary'].to_list()
salaries_22 = df[df['year'] == 2022]['total_gross_salary'].to_list()
stat, p = ttest_ind(salaries_23, salaries_22)
print('Test Statistic: %.3f, p-value: %.10f' % (stat, p))
print('Mean of Salaries from 2023: $%.2f' %(df[df['year'] == 2023]['total_gross_salary'].mean()))
print('Mean of Salaries from 2022: $%.2f' %(df[df['year'] == 2022]['total_gross_salary'].mean()))
Test Statistic: 6.549, p-value: 0.0000000001
Mean of Salaries from 2023: $107966.02
Mean of Salaries from 2022: $102519.92
H0: The means of the samples are equal
H1: The means of the samples are unequal
Because the p-value is less than 0.05, we can reject the null hypothesis that the means of salaries from 2022 are the same as the means of salaries from 2023.
This test is likely not ideal, as both medians are much lower than the calculated means, which implies outliers are effecting the data.
# Mood's Median Test
stat, p, med, tabl = median_test(salaries_23, salaries_22)
print('Test Statistic: %.3f, p-value: %.17f' % (stat, p))
print('Median of Salaries from 2023: $%.2f' %(df[df['year'] == 2023]['total_gross_salary'].median()))
print('Median of Salaries from 2022: $%.2f' %(df[df['year'] == 2022]['total_gross_salary'].median()))
Test Statistic: 62.163, p-value: 0.00000000000000316
Median of Salaries from 2023: $90500.00
Median of Salaries from 2022: $85000.00
H0: The medians of the samples are equal
H1: The medians of the samples are unequal
Because the p-value is less than 0.05, we can reject the null hypothesis that the medians of salaries from 2022 are the same as the medians of salaries from 2023.
2023 USD
The salary prediction will focus on salary prediction in USD for the current year of 2023. This section will focus on analyzing just the 2023 data reported in USD.
aam_usd23 = aam_usd[aam_usd['year'] == 2023]
Breakdown by US State
df = aam_usd23[['form_timestamp','us_state']].groupby(['us_state'], as_index=False).count()
df.loc[df['form_timestamp'] <= 350, 'us_state'] = 'Other'
df = df.groupby(['us_state'], as_index=False).sum()
fig = px.pie(df, names='us_state', values='form_timestamp',
title='Breakdown by State', labels={'us_state':'State', 'form_timestamp':'Responses'})
fig.update_traces(textposition='inside', textinfo='percent+label')
# fig.show()
fig.write_image("fig9.png")
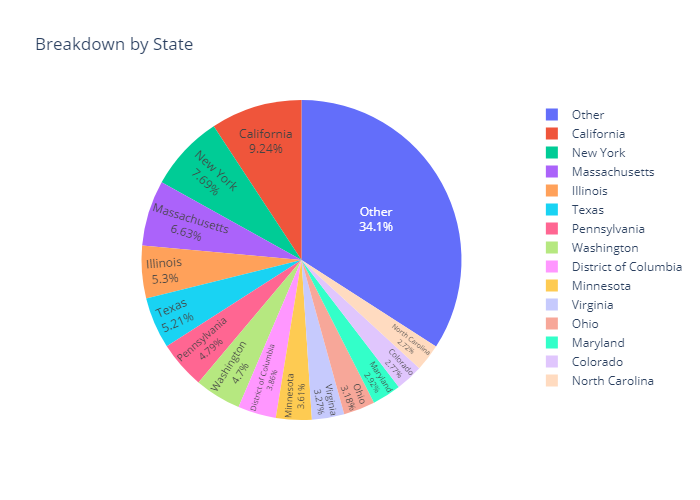
California and New York have the highest number of responses. This is unsurprising, as mainly California and New York are first and third on the list of US states by population.
Breakdown by City
df = aam_usd23
df.loc[df['city'].str.contains('NEW YORK', case=False), 'city'] = 'NEW YORK'
df = df[['form_timestamp','city']].groupby(['city'], as_index=False).count()
df.loc[df['form_timestamp'] <= 150, 'city'] = 'OTHER'
df = df.groupby(['city'], as_index=False).sum()
fig = px.pie(df, names='city', values='form_timestamp',
title='Breakdown by City', labels={'city':'State', 'form_timestamp':'Responses'})
fig.update_traces(textposition='inside', textinfo='percent+label')
# fig.show()
fig.write_image("fig10.png")
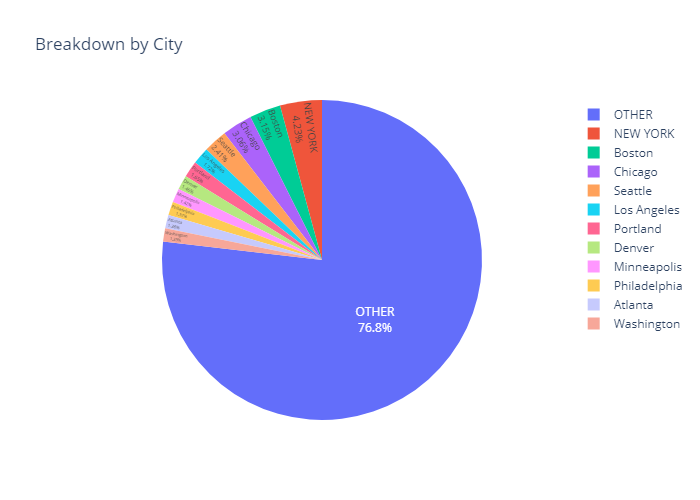
New York (city) has the highest number of responses, followed by Boston and Chicago, which are the other two large and dense metropolitan areas in the US.
Age Group and Total Salary
Overall, age does seem to increase Total Salary, but only to an extent. Also, since the US retirement age is around 65, we see less outliers with the age group of 65 and older because many high earners would likely retire at or around 65.
df = aam_usd23[(aam_usd23['total_gross_salary'] <= 600000)]
fig = px.box(df, x='age_group',y='total_gross_salary', points='outliers', title='Box Plot of Total Salary by Age',
color='age_group', labels={'age_group':'Age Group','total_gross_salary':'Total Salary'},
category_orders={'age_group':{y: x for x, y in aam_usd23[['age_group','age_group_o']].groupby(['age_group','age_group_o'], as_index=False).count().to_dict()['age_group'].items()}})
# fig.show()
fig.write_image("fig11.png")
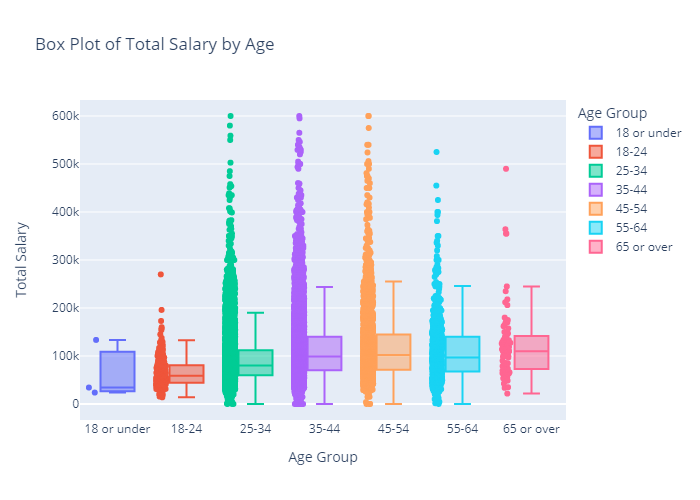
Work Experience and Total Salary
Looking at general work experience, increased work experience does contribute to higher Total Salaries, but like age, it also looks to only increase Total Salary to an extent.
df = aam_usd23[(aam_usd23['total_gross_salary'] <= 600000)]
fig = px.box(df, x='exp_group',y='total_gross_salary', points='outliers', title='Box Plot of Total Salary by Work Experience',
color='exp_group', labels={'exp_group':'Experience Group','total_gross_salary':'Total Salary'},
category_orders={'exp_group': list(aam_usd23[['exp_group','exp_group_o']].groupby(['exp_group','exp_group_o'], as_index=False).count().sort_values('exp_group_o')['exp_group'])})
# fig.show()
fig.write_image("fig12.png")
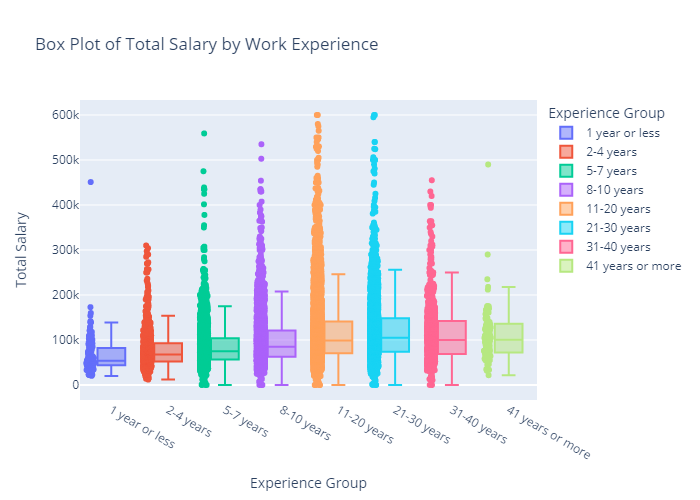
Field Experience and Total Salary
Compared to Total Experience, Field Experience looks to have a higher impact on salary but also seems to level out around 20-30 years of experience.
df = aam_usd23[(aam_usd23['total_gross_salary'] <= 600000)]
fig = px.box(df, x='exp_field_group',y='total_gross_salary', points='outliers', title='Box Plot of Total Gross Salary by Field Experience',
color='exp_field_group', labels={'exp_field_group':'Field Experience Group','total_gross_salary':'Total Salary'},
category_orders={'exp_field_group': list(aam_usd23[['exp_field_group','exp_field_group_o']].groupby(['exp_field_group','exp_field_group_o'], as_index=False).count().sort_values('exp_field_group_o')['exp_field_group'])})
# fig.show()
fig.write_image("fig13.png")
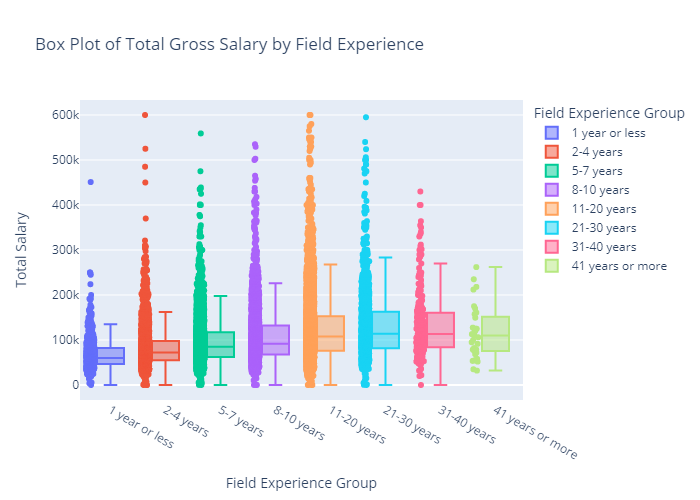
Work Type and Total Salary
Looking at work type, Fully Remote jobs seem to have a higher salary than onsite and hybrid/other positions.
df = aam_usd23[(aam_usd23['total_gross_salary'] <= 600000)]
fig = px.box(df, x='work_type',y='total_gross_salary', points='outliers', title='Box Plot of Total Salary by Work Type',
color='work_type', labels={'work_type':'Work Type','total_gross_salary':'Total Salary'})
# fig.show()
fig.write_image("fig14.png")
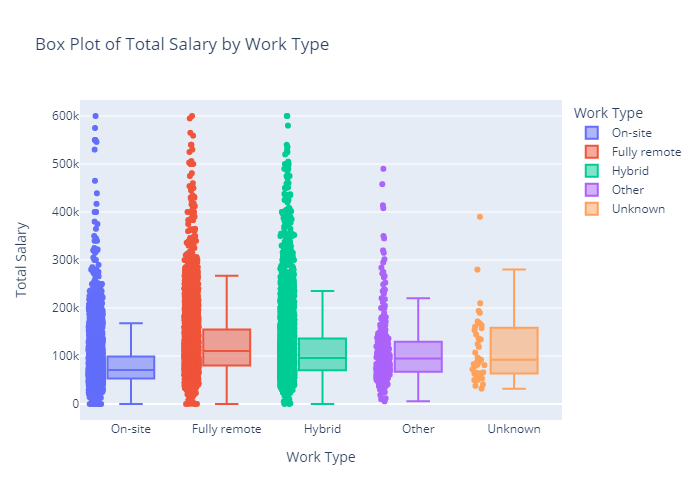
Mood’s Median Test for Differences Between Work Types
# Mood's Median Test
df = aam_usd23[(aam_usd23['total_gross_salary'] <= 600000)]
onsite = df[df['work_type'] == 'On-site']['total_gross_salary'].to_list()
remote = df[df['work_type'] == 'Fully remote']['total_gross_salary'].to_list()
hybrid = df[df['work_type'] == 'Hybrid']['total_gross_salary'].to_list()
other = df[df['work_type'] == 'Other']['total_gross_salary'].to_list()
stat, p, med, tabl = median_test(onsite, remote, hybrid, other)
print('Test Statistic: %.3f, p-value: %.10f' % (stat, p))
print('Median of Onsite Salaries: $%.2f' %(df[df['work_type'] == 'On-site']['total_gross_salary'].median()))
print('Median of Remote Salaries: $%.2f' %(df[df['work_type'] == 'Fully remote']['total_gross_salary'].median()))
print('Median of Hybrid Salaries: $%.2f' %(df[df['work_type'] == 'Hybrid']['total_gross_salary'].median()))
print('Median of Other Salaries: $%.2f' %(df[df['work_type'] == 'Other']['total_gross_salary'].median()))
Test Statistic: 1061.435, p-value: 0.0000000000
Median of Onsite Salaries: $71000.00
Median of Remote Salaries: $110250.00
Median of Hybrid Salaries: $96000.00
Median of Other Salaries: $94925.50
H0: The medians of the samples are equal
H1: The medians of the samples are unequal
Because the p-value is less than 0.05, we can reject the null hypothesis that the medians of salaries by work type are all the same. This test does not tell us which work type’s salaries comparatively are different to each other.
Gender and Total Salary
df = aam_usd23[(aam_usd23['total_gross_salary'] <= 600000)]
fig = px.box(df, x='gender',y='total_gross_salary', points='outliers', title='Box Plot of Total Salary by Gender',
color='gender', labels={'gender':'Gender','total_gross_salary':'Total Salary'})
# fig.show()
fig.write_image("fig15.png")
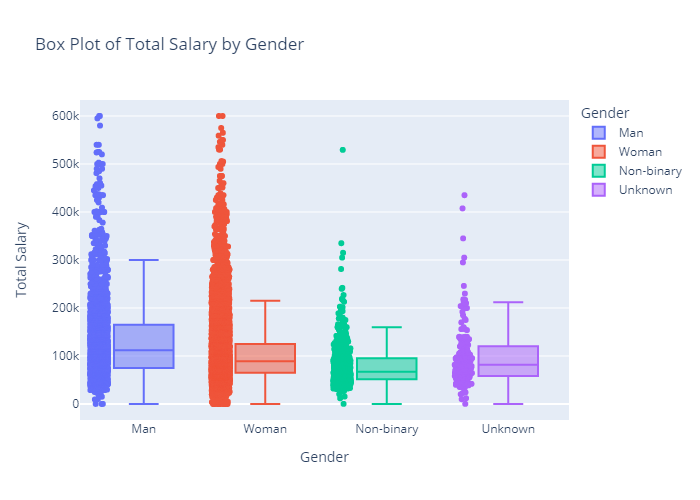
H0: The medians of the samples are equal
H1: The medians of the samples are unequal
Because the p-value is less than 0.05, we can reject the null hypothesis that the medians of salaries by gender are all the same. However, this may be caused by a different distribution of industries, functional areas, years of experience, or any number of factors outside of gender.
Mood’s Median Test for Differences Between Genders
# Mood's Median Test
df = aam_usd23[(aam_usd23['total_gross_salary'] <= 600000)]
man = df[df['gender'] == 'Man']['total_gross_salary'].to_list()
woman = df[df['gender'] == 'Woman']['total_gross_salary'].to_list()
stat, p, med, tabl = median_test(man, woman)
print('Test Statistic: %.3f, p-value: %.10f' % (stat, p))
print('Median of Male Salaries: $%.2f' %(df[df['gender'] == 'Man']['total_gross_salary'].median()))
print('Median of Female Salaries: $%.2f' %(df[df['gender'] == 'Woman']['total_gross_salary'].median()))
Test Statistic: 209.090, p-value: 0.0000000000
Median of Male Salaries: $112000.00
Median of Female Salaries: $89000.00
Predicting Salary
Because of outliers, we will only train the total salary (base salary + bonus) prediction on responses from 2023 in USD below $600,000. While some jobs do make upwards of $600,000, these positions are the minority and would most likely be CEOs, C-Suites in large companies, and business owners.
# Preprocessing Skip
aam = pd.read_csv('aam_clean.csv')
aam_cluster = pd.read_csv('aam_usd_cluster.csv')
aam_cluster = aam_cluster.astype({'cluster':'string'})
# Join with Cluster Association
aam = aam.merge(aam_cluster[['job_title','cluster']], how='left', on=['job_title'])
# Only 2023 Data in USD under $600k
aam_usd = aam[aam['currency'] == 'USD']
aam_usd23 = aam_usd[aam_usd['year'] == 2023]
aam_usd23_f = aam_usd23[(aam_usd23['total_gross_salary'] <= 600000)]
aam_usd23_f = aam_usd23_f.drop(columns={'form_timestamp','add_job_context','currency',
'currency_text','add_job_context','add_salary_context',
'city'})
# Load K-Means Model
k_means_final_model = pickle.load(open('kmeans_final_model.sav', 'rb'))
We can start by building two pipelines, one with the job title cluster and one without. These will be used to compare the final selected model against to see if the job clustering positively impacts the prediction model, or if it’s better without the clustering.
# Pipeline
numeric_features = ['age_group_o','exp_group_o','exp_field_group_o', 'education_o']
numeric_transformer = Pipeline( #no missing values, so no need for an imputer
steps=[('scaler', StandardScaler())]
)
categorical_features = ['industry','functional_area','work_type','us_state','gender','race','cluster']
categorical_transformer = Pipeline(
steps=[('encoder',OneHotEncoder(handle_unknown='error'))]
)
preprocessor = ColumnTransformer(
transformers = [
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
]
)
salary_pipeline = Pipeline(
steps=[('preprocessor', preprocessor)
], verbose=True
)
# 2nd Pipeline (no Job Cluster)
numeric_features = ['age_group_o','exp_group_o','exp_field_group_o', 'education_o']
numeric_transformer = Pipeline( #no missing values, so no need for an imputer
steps=[('scaler', StandardScaler())]
)
categorical_features = ['industry','functional_area','work_type','us_state','gender','race']
categorical_transformer = Pipeline(
steps=[('encoder',OneHotEncoder(handle_unknown='error'))]
)
preprocessor = ColumnTransformer(
transformers = [
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
]
)
salary_pipeline2 = Pipeline(
steps=[('preprocessor', preprocessor)
], verbose=True
)
We will now split the data into training and testing sets (70:30 split) and run the data through each pipeline. Unfortunately, due to some clusters only having 1 member, we must run the pipeline before splitting the data to ensure the training and test set have the same dimensions.
# Train Test Split
X = aam_usd23_f.loc[:, ~aam_usd23_f.columns.isin(['total_gross_salary','combined_title',
'combined_title_vector','age_group','gross_salary','bonus','exp_group','exp_field_group'
'education','year','country','job_title','exp_field_group','education','job_title_vector'])]
y = aam_usd23_f['total_gross_salary']
X_p = salary_pipeline.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_p,y,test_size=0.3, random_state=101)
[Pipeline] ...... (step 1 of 1) Processing preprocessor, total= 0.0s
# Train Test Split2
X2 = aam_usd23_f.loc[:, ~aam_usd23_f.columns.isin(['total_gross_salary','combined_title',
'combined_title_vector','age_group','gross_salary','bonus','exp_group','exp_field_group'
'education','year','country','job_title','exp_field_group','education','job_title_vector'])]
y2 = aam_usd23_f['total_gross_salary']
X2_p = salary_pipeline2.fit_transform(X)
X2_train, X2_test, y2_train, y2_test = train_test_split(X2_p,y2,test_size=0.3, random_state=101)
[Pipeline] ...... (step 1 of 1) Processing preprocessor, total= 0.0s
Modeling
As this data has a lot of categorical and ordinal dimensions, we will train many different models and assess metrics like R^2, Explained Variance, Means Absolute Error, Mean Squared Error, and Mean Absolute Perecnt Error. We want to maximize the R^2 and Explained Variance value and minimize all other values.
# Linear Regression
from sklearn import linear_model
from sklearn import metrics
lm_salary = linear_model.LinearRegression().fit(X_train, y_train)
pickle.dump(lm_salary, open('lm_salary.sav', 'wb')) #save model
lm_predict = lm_salary.predict(X_test)
# Scoring
print('R2 Score:', metrics.r2_score(y_test, lm_predict))
print('Explained Variance: %.2f' %(metrics.explained_variance_score(y_test, lm_predict)))
print('Mean Absolute Error: %.2f' %(metrics.mean_absolute_error(y_test, lm_predict)))
print('Mean Squared Error: %.2f' %(metrics.mean_squared_error(y_test, lm_predict)))
print('Mean Absolute Percent Error: %.2f' %(metrics.mean_absolute_percentage_error(y_test, lm_predict)*100),'%')
R2 Score: 0.38077800440154486
Explained Variance: 0.38
Mean Absolute Error: 34003.63
Mean Squared Error: 2535402735.74
Mean Absolute Percent Error: 121.89 %
# Decision Tree
from sklearn import tree
tree_salary = tree.DecisionTreeClassifier().fit(X_train, y_train)
# pickle.dump(tree_salary, open('tree_salary.sav', 'wb')) #save model
tree_predict = tree_salary.predict(X_test)
# Scoring
print('R2 Score:', metrics.r2_score(y_test, tree_predict))
print('Explained Variance: %.2f' %(metrics.explained_variance_score(y_test, tree_predict)))
print('Mean Absolute Error: %.2f' %(metrics.mean_absolute_error(y_test, tree_predict)))
print('Mean Squared Error: %.2f' %(metrics.mean_squared_error(y_test, tree_predict)))
print('Mean Absolute Percent Error: %.2f' %(metrics.mean_absolute_percentage_error(y_test, tree_predict)*100),'%')
R2 Score: -0.16609841319649865
Explained Variance: -0.16
Mean Absolute Error: 45433.90
Mean Squared Error: 4774586703.92
Mean Absolute Percent Error: 108.99 %
# Kernel Ridge Regression
from sklearn.kernel_ridge import KernelRidge
kernel_salary = KernelRidge(kernel='poly').fit(X_train, y_train)
pickle.dump(kernel_salary, open('kernel_salary.sav', 'wb')) #save model
kernal_predict = kernel_salary.predict(X_test)
# Scoring
print('R2 Score:', metrics.r2_score(y_test, kernal_predict))
print('Explained Variance: %.2f' %(metrics.explained_variance_score(y_test, kernal_predict)))
print('Mean Absolute Error: %.2f' %(metrics.mean_absolute_error(y_test, kernal_predict)))
print('Mean Squared Error: %.2f' %(metrics.mean_squared_error(y_test, kernal_predict)))
print('Mean Absolute Percent Error: %.2f' %(metrics.mean_absolute_percentage_error(y_test, kernal_predict)*100),'%')
R2 Score: 0.3577367695180159
Explained Variance: 0.36
Mean Absolute Error: 33675.18
Mean Squared Error: 2629745007.78
Mean Absolute Percent Error: 113.38 %
# Random Forest Regression
from sklearn.ensemble import RandomForestRegressor
rfr_salary = RandomForestRegressor().fit(X_train, y_train)
pickle.dump(rfr_salary, open('rfr_salary.sav', 'wb')) #save model
rfr_predict = rfr_salary.predict(X_test)
# Scoring
print('R2 Score:', metrics.r2_score(y_test, rfr_predict))
print('Explained Variance: %.2f' %(metrics.explained_variance_score(y_test, rfr_predict)))
print('Mean Absolute Error: %.2f' %(metrics.mean_absolute_error(y_test, rfr_predict)))
print('Mean Squared Error: %.2f' %(metrics.mean_squared_error(y_test, rfr_predict)))
print('Mean Absolute Percent Error: %.2f' %(metrics.mean_absolute_percentage_error(y_test, rfr_predict)*100),'%')
R2 Score: 0.40027815456347093
Explained Variance: 0.41
Mean Absolute Error: 31805.32
Mean Squared Error: 2455559425.23
Mean Absolute Percent Error: 109.46 %
# General Linear Model
from sklearn.linear_model import TweedieRegressor
glm_salary = TweedieRegressor(power=0).fit(X_train, y_train)
pickle.dump(glm_salary, open('glm_salary.sav', 'wb')) #save model
glm_predict = glm_salary.predict(X_test)
# Scoring
print('R2 Score:', metrics.r2_score(y_test, glm_predict))
print('Explained Variance: %.2f' %(metrics.explained_variance_score(y_test, glm_predict)))
print('Mean Absolute Error: %.2f' %(metrics.mean_absolute_error(y_test, glm_predict)))
print('Mean Squared Error: %.2f' %(metrics.mean_squared_error(y_test, glm_predict)))
print('Mean Absolute Percent Error: %.2f' %(metrics.mean_absolute_percentage_error(y_test, glm_predict)*100),'%')
R2 Score: 0.1643036042042263
Explained Variance: 0.16
Mean Absolute Error: 40307.83
Mean Squared Error: 3421756564.22
Mean Absolute Percent Error: 126.88 %
# Stochastic Gradient Descent (SGD)
from sklearn.linear_model import SGDRegressor
sgd_salary = SGDRegressor().fit(X_train, y_train)
pickle.dump(sgd_salary, open('sgd_salary.sav', 'wb')) #save model
sgd_predict = sgd_salary.predict(X_test)
# Scoring
print('R2 Score:', metrics.r2_score(y_test, sgd_predict))
print('Explained Variance: %.2f' %(metrics.explained_variance_score(y_test, sgd_predict)))
print('Mean Absolute Error: %.2f' %(metrics.mean_absolute_error(y_test, sgd_predict)))
print('Mean Squared Error: %.2f' %(metrics.mean_squared_error(y_test, sgd_predict)))
print('Mean Absolute Percent Error: %.2f' %(metrics.mean_absolute_percentage_error(y_test, sgd_predict)*100),'%')
R2 Score: 0.448628214796173
Explained Variance: 0.45
Mean Absolute Error: 31829.85
Mean Squared Error: 2257590238.32
Mean Absolute Percent Error: 120.81 %
# Support Vector Machine
from sklearn import svm
svm_salary = svm.SVR().fit(X_train, y_train)
pickle.dump(svm_salary, open('svm_salary.sav', 'wb')) #save model
svm_predict = svm_salary.predict(X_test)
# Scoring
print('R2 Score:', metrics.r2_score(y_test, svm_predict))
print('Explained Variance: %.2f' %(metrics.explained_variance_score(y_test, svm_predict)))
print('Mean Absolute Error: %.2f' %(metrics.mean_absolute_error(y_test, svm_predict)))
print('Mean Squared Error: %.2f' %(metrics.mean_squared_error(y_test, svm_predict)))
print('Mean Absolute Percent Error: %.2f' %(metrics.mean_absolute_percentage_error(y_test, svm_predict)*100),'%')
R2 Score: -0.0785405894740474
Explained Variance: 0.00
Mean Absolute Error: 43238.36
Mean Squared Error: 4416081438.64
Mean Absolute Percent Error: 112.75 %
# Gaussian Process Regressor
from sklearn.gaussian_process import GaussianProcessRegressor
gpr_salary = GaussianProcessRegressor().fit(X_train.toarray(), y_train)
# pickle.dump(gpr_salary, open('gpr_salary.sav', 'wb')) #save model
gpr_predict = gpr_salary.predict(X_test.toarray())
# Scoring
print('R2 Score:', metrics.r2_score(y_test, gpr_predict))
print('Explained Variance: %.2f' %(metrics.explained_variance_score(y_test, gpr_predict)))
print('Mean Absolute Error: %.2f' %(metrics.mean_absolute_error(y_test, gpr_predict)))
print('Mean Squared Error: %.2f' %(metrics.mean_squared_error(y_test, gpr_predict)))
print('Mean Absolute Percent Error: %.2f' %(metrics.mean_absolute_percentage_error(y_test, gpr_predict)*100),'%')
R2 Score: 0.21271365619485783
Explained Variance: 0.28
Mean Absolute Error: 35787.31
Mean Squared Error: 3223541741.22
Mean Absolute Percent Error: 124.06 %
From the above results, the Random Forest Regressor and the Stochastic Gradient Descent (SGD) models perform the best. The SGD model has a higher R^2 and Explained Variance values, but also has higher error metrics compared to the Random Forest Regressor.
The models overall, however, are not well trained; there is still lots of room for model improvements outside of this project.
Predicted vs. Actuals
We can investigate the poor fit of the models by plotting the fitted values vs. the actual salaries for the training data.
# RFR Fitted vs. Predicted
rfr_predict = rfr_salary.predict(X_test)
line_x = list(range(0,600000,1000))
line_y = list(range(0,600000,1000))
d = {'rfr_predict':rfr_predict, 'y_test':y_test}
df = pd.DataFrame(d)
df['dif'] = df['rfr_predict'] - df['y_test']
df['dif_cat'] = np.where(df['dif'] >= 0, '#EF553B','#636EFA')
fig = go.Figure()
fig.add_trace(go.Scatter(x=df['rfr_predict'],y=df['y_test'], mode='markers', marker_color=df['dif_cat']))
fig.add_trace(go.Scatter(x=line_x, y=line_y, marker_color='black'))
fig.update_layout(title='RFR Fitted vs. Actuals')
fig.update_xaxes(title_text="Predicted")
fig.update_yaxes(title_text="Actual")
fig.update_layout(showlegend=False)
fig.update_layout(yaxis_range=[0,max(rfr_predict)], xaxis_range=[0,max(y_test)])
# fig.show()
fig.write_image('fig_19.png')
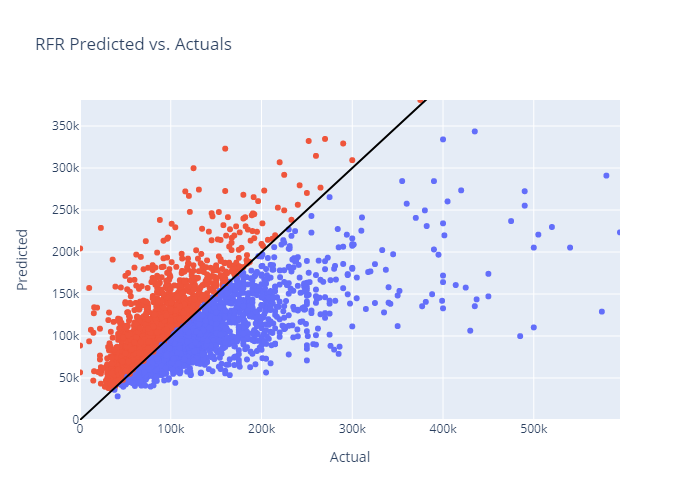
df[['dif_cat2','dif']].groupby(['dif_cat2']).count()
| dif | |
|---|---|
| dif_cat2 | |
| Above | 1900 |
| Below | 2000 |
From the plot and table above, the Random Forest Regression model is under predicting more often than over-predicting. Looking at the graph, at lower actual values, the model tends to over-predict salary; however, at higher actual salaries, the model seems to under-predict. Similarly, the higher the actual salary the worse the prediction gets.
# SGD Fitted vs. Predicted
sgd_predict = sgd_salary.predict(X_test)
line_x = list(range(0,600000,1000))
line_y = list(range(0,600000,1000))
d = {'sgd_predict':sgd_predict, 'y_test':y_test}
df = pd.DataFrame(d)
df['dif'] = df['sgd_predict'] - df['y_test']
df['dif_cat'] = np.where(df['dif'] >= 0, '#EF553B','#636EFA')
fig = go.Figure()
fig.add_trace(go.Scatter(x=df['sgd_predict'],y=df['y_test'], mode='markers', marker_color=df['dif_cat']))
fig.add_trace(go.Scatter(x=line_x, y=line_y, marker_color='black'))
fig.update_layout(title='SGD Fitted vs. Actuals')
fig.update_xaxes(title_text="Predicted")
fig.update_yaxes(title_text="Actual")
fig.update_layout(showlegend=False)
fig.update_layout(yaxis_range=[0,max(sgd_predict)], xaxis_range=[0,max(y_test)])
# fig.show()
fig.write_image('fig_20.png')
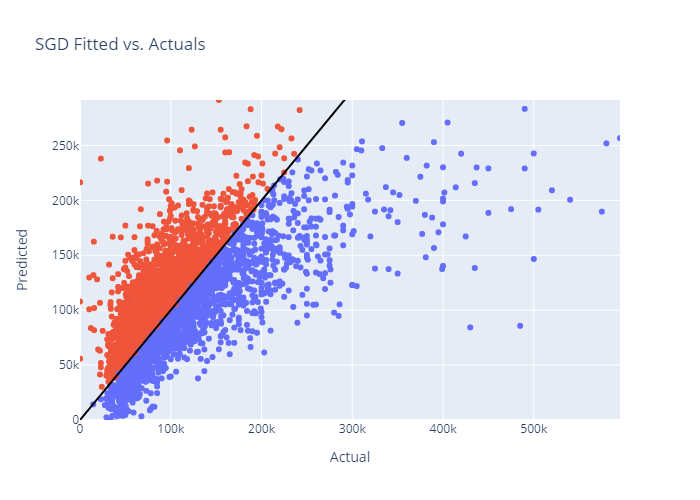
df[['dif_cat2','dif']].groupby(['dif_cat2']).count()
| dif | |
|---|---|
| dif_cat2 | |
| Above | 1764 |
| Below | 2136 |
From the plot and table above, the Stochastic Gradient Descent (SGD) model is also under predicting more often than over-predicting. Looking at the graph, at lower actual values, the model tends to over-predict salary, even moreso than the Random Forest Regressor (RFR); however, at higher actual salaries, the model seems to under-predict. At higher salaries comparatively, the SGD model seems to fit around the line y=x (or the fitted values = actual values) much better than the RFR model.
Modeling Without Job Title Cluster
We can now run the two selected models from above on the data that does not include the job cluster as an input to the model.
# Random Forest Regression
from sklearn.ensemble import RandomForestRegressor
rfr2_salary = RandomForestRegressor().fit(X2_train, y2_train)
pickle.dump(rfr2_salary, open('rfr2_salary.sav', 'wb')) #save model
rfr2_predict = rfr2_salary.predict(X2_test)
# Scoring
print('R2 Score:', metrics.r2_score(y_test, rfr2_predict))
print('Explained Variance: %.2f' %(metrics.explained_variance_score(y2_test, rfr2_predict)))
print('Mean Absolute Error: %.2f' %(metrics.mean_absolute_error(y2_test, rfr2_predict)))
print('Mean Squared Error: %.2f' %(metrics.mean_squared_error(y2_test, rfr2_predict)))
print('Mean Absolute Percent Error: %.2f' %(metrics.mean_absolute_percentage_error(y2_test, rfr2_predict)*100),'%')
R2 Score: 0.36343613227955796
Explained Variance: 0.36
Mean Absolute Error: 33047.36
Mean Squared Error: 2606408982.83
Mean Absolute Percent Error: 109.91 %
# Stochastic Gradient Descent (SGD)
from sklearn.linear_model import SGDRegressor
sgd2_salary = SGDRegressor().fit(X2_train, y2_train)
pickle.dump(sgd2_salary, open('sgd2_salary.sav', 'wb')) #save model
sgd2_predict = sgd2_salary.predict(X2_test)
# Scoring
print('R2 Score:', metrics.r2_score(y2_test, sgd2_predict))
print('Explained Variance: %.2f' %(metrics.explained_variance_score(y2_test, sgd2_predict)))
print('Mean Absolute Error: %.2f' %(metrics.mean_absolute_error(y2_test, sgd2_predict)))
print('Mean Squared Error: %.2f' %(metrics.mean_squared_error(y2_test, sgd2_predict)))
print('Mean Absolute Percent Error: %.2f' %(metrics.mean_absolute_percentage_error(y2_test, sgd2_predict)*100),'%')
R2 Score: 0.39677168059756973
Explained Variance: 0.40
Mean Absolute Error: 33018.75
Mean Squared Error: 2469916673.12
Mean Absolute Percent Error: 114.84 %
From the calculated metrics, both models performed worse without the job cluster, so while not perfect, the job cluster did help the model improve predictions for total salary.
Predicting
We can now create functions to predict salary based on various attributes.
# Helper Tables
age_groups = pd.DataFrame(np.unique(aam_usd23['age_group']), columns = {'group'})
age_groups['levels'] = [1,2,3,4,5,6,7]
age_groups['min'] = [0,18,25,35,45,55,65]
age_groups['max'] = [17,24,34,44,54,64,120]
exp_groups = pd.DataFrame(np.unique(aam_usd23['exp_group']), columns = {'group'})
exp_groups['levels'] = [1,5,2,6,7,8,3,4]
exp_groups['min'] = [0,11,2,21,31,41,5,8]
exp_groups['max'] = [1,20,4,30,40,120,7,10]
edu_groups = pd.DataFrame(np.unique(aam_usd23['education']), columns = {'group'})
edu_groups['levels'] = [3,1,4,6,5,2]
X = aam_usd23_f.loc[:, ~aam_usd23_f.columns.isin(['total_gross_salary','combined_title',
'combined_title_vector','age_group','gross_salary','bonus','exp_group','exp_field_group'
'education','year','country','job_title','exp_field_group','education','job_title_vector'])]
# Models
rfr_salary = pickle.load(open('rfr_salary.sav', 'rb'))
sgd_salary = pickle.load(open('sgd_salary.sav', 'rb'))
# Helper Functions
def job_title_to_cluster(job_text):
fh = FeatureHasher(input_type='string', n_features=1000).transform(job_text)
arry = k_means_final_model.predict(fh)
return max(arry)
def predict_salary(age, exp, field_exp, education, industry, functional_area, work_type, us_state, gender, \
race, job_title, model):
education = education.lstrip().rstrip()
industry = industry.upper().lstrip().rstrip()
functional_area = functional_area.upper().lstrip().rstrip()
work_type = work_type.lstrip().rstrip()
us_state = us_state.lstrip().rstrip()
gender = gender.lstrip().rstrip()
race = race.lstrip().rstrip()
job_title = job_title.upper().lstrip().rstrip()
age = int(age)
exp = int(exp)
field_exp = int(field_exp)
cat_vars = ['education', 'industry', 'functional_area', 'work_type', 'us_state', 'gender', 'race']
cat_vars_vals = [education, industry, functional_area, work_type, us_state, gender, race]
predict_cols = ['industry', 'functional_area', 'us_state', 'work_type', 'gender', \
'race', 'age_group_o', 'exp_group_o', 'exp_field_group_o', \
'education_o', 'cluster']
# Quitting Early
if (isinstance(age, int) == False) | (age < 1) | (age > 120) :
return 'Age Must Be An Integer Above 1 and Below 120'
if (isinstance(exp, int) == False) | (exp < 0) | (exp > 120):
return 'Experience Must Be An Integer Above 0 and Below 120'
if (isinstance(field_exp, int) == False) | (field_exp < 0) | (field_exp > 120):
return 'Field Experience Must Be An Integer Above 0 and Below 120'
if (age <= exp) | (age <= field_exp):
return 'Age Must Be Higher than Experience'
for l in range(len(cat_vars)):
if (cat_vars_vals[l] not in (np.unique(aam_usd23[cat_vars[l]]))):
return print(cat_vars[l].capitalize() +' Not In List. Enter New Value', '\n Values:', \
np.unique(aam_usd23[cat_vars[l]]))
if model not in ['RFR','SGD']:
return 'Not A Valid Model. Please Select From RFR (Random Forest Regressor) or SGD (Stochastic Gradient Descent)'
# Cluster from Job Title
cluster = str(job_title_to_cluster(job_title))
# Finding Levels for Ordinal Variables
for i in range(len(age_groups)):
if (age >= age_groups['min'][i]) & (age <= age_groups['max'][i]):
age_group_o = age_groups['levels'][i]
for i in range(len(exp_groups)):
if (exp >= exp_groups['min'][i]) & (exp <= exp_groups['max'][i]):
exp_group_o = exp_groups['levels'][i]
for i in range(len(exp_groups)):
if (field_exp >= exp_groups['min'][i]) & (field_exp <= exp_groups['max'][i]):
exp_field_group_o = exp_groups['levels'][i]
for i in range(len(edu_groups)):
if (education == edu_groups['group'][i]):
education_o = edu_groups['levels'][i]
# Creating Table
predict_vals = [industry, functional_area, us_state, work_type, gender, \
race, age_group_o, exp_group_o, exp_field_group_o, \
education_o, cluster]
temp_df = pd.DataFrame(columns=predict_cols)
temp_df.loc[len(temp_df)] = predict_vals
# Running Through Pipeline
X_temp = salary_pipeline.fit(X).transform(temp_df)
# Returning Prediction
if model == 'RFR':
return print('RFR Salary Estimate: $%.2f' %(rfr_salary.predict(X_temp)))
if model == 'SGD':
return print('SGD Salary Estimate: $%.2f' %(sgd_salary.predict(X_temp)))
# age, exp, field_exp, education, industry, functional_area, work_type, us_state, gender, race, job_title, model
rfr_prediction = predict_salary(24, 3, 1, "College degree", 'TRANSPORT OR LOGISTICS', 'COMPUTING OR TECH', 'Fully remote', 'Colorado' \
, 'Woman', 'Asian or Asian American', 'Data Analyst', 'RFR')
sgd_prediction = rfr_prediction = predict_salary(24, 3, 1, "College degree", 'TRANSPORT OR LOGISTICS', 'COMPUTING OR TECH', 'Fully remote', 'Colorado' \
, 'Woman', 'Asian or Asian American', 'Data Analyst', 'SGD')
RFR Salary Estimate: $78250.04
SGD Salary Estimate: $140464.14
The predictions above are fairly interesting. The above information is my responses to the 2023 survey. The first salary estimate is below what I currently make. The second estimate is way above what I make (but would love to make that much money one day). This overall seems in line with the metrics associated with the model predicted; RFR had lower residual metrics while SGD had better fit metrics.
Final Thoughts and Project Next Steps
This project was definingly not perfect. At all stages in the process, decisions were made that had downstream implications on the analysis and modeling. A few next steps that loosen some of these decisions are:
- Allow for multiple responses in analysis
- Redo survey with US Labor Job Categories (Standard Occupational Classifications) instead of free text responses
- Test more advanced methods to group job title (e.g. neural networks) or attempt to pre-label some job titles to classify instead of cluster
- Expand Analysis and Modeling to Non-US Countries by adding a table for currency conversion
- Develop or Test Advanced Natural Language Processing Solutions to Better Categorize Industries, Functional Areas, and Job Titles
- Drop clusters with fewer than 2 members for pipelining on train/test split data
- Allow for salaries over $600,000 or find a more mathematical way to find the cutoff point
Overall though, this was an interesting project to attempt and helped me develop my skills in python for data science.
Additional Retrospective Potential Updates
In addition to the project next steps listed above, there are a few data splitting related issues in the project above that I would ideally like to correct at some point, but may not have time to.
The main issue is the inclusion of all data in the clustering method, and the subsequent train test split. All data was run through the clustering algorithm to create the best clusters for all data; however, in a true experiment, the training data used to validate the prediction algorithm should also be held from the cluster fitting. The training data thus should be run through the cluster assignment after cluster fitting and then predicted from the final prediction model. This ensures no data snooping is done. While thought about, since both models’ performance was poor, this can be left as a though exercise and not implemented.