DTSA 5511 - Predicting AI Generated Text
As AI becomes more prevalent and usable with the release and continued innovations of Generative AIs like ChatGPT and Bard, more and more people are turning to these Generative AIs to create content. While creating content like pictures, music, or text, using Generative AIs is not inherently negative, creating AI content without citation can be misleading or even plagiarism.
Essays are used in academia as a way to test student’s knowledge of the topic or topics, as well as a way to further research and learning in a specific area. Students who use Generative AIs to write essays for them not only miss out on additional learning and skill building from researching and writing an essay, for many schools and educational institutions, using an AI without citation is considered plagiarism and could lead to or disciplinary actions or even expulsion. Additionally, while Generative AIs can write essays, they are not perfect and can sometimes include incorrect information or fail to answer the prompt provided.
While some cases of Generative AI plagiarism is obvious, individual teachers may not be able to scrutinize every single essay a student writes. For this reason, it is important to develop tools to detect AI generated text. This project will use the dataset from the LLM-Detect AI Generated Text Kaggle Competition to attempt to accurately detect AI generated essays. In contrast to the competition, we will instead focus on predicting AI vs non-AI essays from a smaller portion of the provided text and compare results to traditional Machine Learning Models (supervised and unsupervised).
Data Citation:
The Learning Agency Lab. (2023, October 31). LLM - detect AI generated text. LLM - Detect AI Generated Text. https://www.kaggle.com/competitions/llm-detect-ai-generated-text
# Libraries
import pandas as pd
import numpy as np
## String manipulation
import string
import random
import re
## NLP
import spacy
nlp = spacy.load("en_core_web_sm")
import tensorflow_text as text
## Math
import math
# Data Visualization
import matplotlib.pyplot as plt
# Time
import time
# Sklearn Pipeline
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.model_selection import train_test_split
# Sklearn Models
from sklearn.decomposition import NMF
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
# Metrics
from sklearn.metrics import accuracy_score, auc, confusion_matrix, f1_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Deep Learning
import keras
import tensorflow as tf
from keras import layers
from tensorflow.keras import utils
import tensorflow_hub as hub
from keras import Sequential
from keras.layers import Dense, Dropout, Flatten, Embedding, LSTM, Dense, TextVectorization
from keras.optimizers import Adam
/opt/conda/lib/python3.10/site-packages/scipy/__init__.py:146: UserWarning: A NumPy version >=1.16.5 and <1.23.0 is required for this version of SciPy (detected version 1.24.3
warnings.warn(f"A NumPy version >={np_minversion} and <{np_maxversion}"
Data Exploration
train_essays = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/train_essays.csv')
# final_test_essays = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/test_essays.csv')
train_prompts = pd.read_csv('/kaggle/input/llm-detect-ai-generated-text/train_prompts.csv')
print('Train Essays:', len(train_essays))
# print('Test Essays:', len(final_test_essays))
print('Train Prompts:', len(train_prompts))
Train Essays: 1378
Train Prompts: 2
train_essays
| id | prompt_id | text | generated | |
|---|---|---|---|---|
| 0 | 0059830c | 0 | Cars. Cars have been around since they became ... | 0 |
| 1 | 005db917 | 0 | Transportation is a large necessity in most co... | 0 |
| 2 | 008f63e3 | 0 | "America's love affair with it's vehicles seem... | 0 |
| 3 | 00940276 | 0 | How often do you ride in a car? Do you drive a... | 0 |
| 4 | 00c39458 | 0 | Cars are a wonderful thing. They are perhaps o... | 0 |
| ... | ... | ... | ... | ... |
| 1373 | fe6ff9a5 | 1 | There has been a fuss about the Elector Colleg... | 0 |
| 1374 | ff669174 | 0 | Limiting car usage has many advantages. Such a... | 0 |
| 1375 | ffa247e0 | 0 | There's a new trend that has been developing f... | 0 |
| 1376 | ffc237e9 | 0 | As we all know cars are a big part of our soci... | 0 |
| 1377 | ffe1ca0d | 0 | Cars have been around since the 1800's and hav... | 0 |
1378 rows × 4 columns
There are 1,378 essays from two prompts. We can now look at the distribution of these essays, as well as some example texts and general features.
df = pd.DataFrame(train_essays['prompt_id'].value_counts()).reset_index()
fig, ax = plt.subplots()
ax.bar(df['prompt_id'],df['count'], color=['tab:blue','tab:orange'])
ax.set_ylabel('Count')
ax.set_xlabel('Prompt')
ax.set_title('Count of Prompts')
plt.show()

The prompts look fairly evenly distributed.
df = pd.DataFrame(train_essays['generated'].value_counts()).reset_index()
fig, ax = plt.subplots()
ax.bar(df['generated'],df['count'], color=['tab:blue','tab:orange'])
ax.set_ylabel('Count')
ax.set_xlabel('AI Generated')
ax.set_title('Count of Generated Essays')
plt.show()

Unfortunately, in the original dataset, there are not many AI Generated essays. We will need to either replicate these generated entries or ‘create’ new entries based on the provided prompts. Before doing this, we can look at some essay texts.
take = 3
for i in range(take):
print('Essay ',i,':')
print(train_essays[train_essays['generated'] == 0].reset_index().loc[i]['text'])
print('')
Essay 0 :
Cars. Cars have been around since they became famous in the 1900s, when Henry Ford created and built the first ModelT. Cars have played a major role in our every day lives since then. But now, people are starting to question if limiting car usage would be a good thing. To me, limiting the use of cars might be a good thing to do.
In like matter of this, article, "In German Suburb, Life Goes On Without Cars," by Elizabeth Rosenthal states, how automobiles are the linchpin of suburbs, where middle class families from either Shanghai or Chicago tend to make their homes. Experts say how this is a huge impediment to current efforts to reduce greenhouse gas emissions from tailpipe. Passenger cars are responsible for 12 percent of greenhouse gas emissions in Europe...and up to 50 percent in some carintensive areas in the United States. Cars are the main reason for the greenhouse gas emissions because of a lot of people driving them around all the time getting where they need to go. Article, "Paris bans driving due to smog," by Robert Duffer says, how Paris, after days of nearrecord pollution, enforced a partial driving ban to clear the air of the global city. It also says, how on Monday, motorist with evennumbered license plates were ordered to leave their cars at home or be fined a 22euro fine 31. The same order would be applied to oddnumbered plates the following day. Cars are the reason for polluting entire cities like Paris. This shows how bad cars can be because, of all the pollution that they can cause to an entire city.
Likewise, in the article, "Carfree day is spinning into a big hit in Bogota," by Andrew Selsky says, how programs that's set to spread to other countries, millions of Columbians hiked, biked, skated, or took the bus to work during a carfree day, leaving streets of this capital city eerily devoid of traffic jams. It was the third straight year cars have been banned with only buses and taxis permitted for the Day Without Cars in the capital city of 7 million. People like the idea of having carfree days because, it allows them to lesson the pollution that cars put out of their exhaust from people driving all the time. The article also tells how parks and sports centers have bustled throughout the city uneven, pitted sidewalks have been replaced by broad, smooth sidewalks rushhour restrictions have dramatically cut traffic and new restaurants and upscale shopping districts have cropped up. Having no cars has been good for the country of Columbia because, it has aloud them to repair things that have needed repairs for a long time, traffic jams have gone down, and restaurants and shopping districts have popped up, all due to the fact of having less cars around.
In conclusion, the use of less cars and having carfree days, have had a big impact on the environment of cities because, it is cutting down the air pollution that the cars have majorly polluted, it has aloud countries like Columbia to repair sidewalks, and cut down traffic jams. Limiting the use of cars would be a good thing for America. So we should limit the use of cars by maybe riding a bike, or maybe walking somewhere that isn't that far from you and doesn't need the use of a car to get you there. To me, limiting the use of cars might be a good thing to do.
Essay 1 :
Transportation is a large necessity in most countries worldwide. With no doubt, cars, buses, and other means of transportation make going from place to place easier and faster. However there's always a negative pollution. Although mobile transportation are a huge part of daily lives, we are endangering the Earth with harmful greenhouse gases, which could be suppressed.
A small suburb community in Germany called Vauban, has started a "carfree" lifestyle. In this city, markets and stores are placed nearby homes, instead of being located by farend highways. Although Vauban is not completely carfree, 70% of Vauban families do not own cars Even a large 57% of families stated to have sold their cars to move to Vauban. Some families have even said to be less stressed depending on car transportation. Cars are responsible for about 12% of greenhouse gases, and can even be up to 50% in some carintensive areas in the United States.
Another insight to reduced car zones brings Paris' incident with smog. Paris' officials created a system that would in fact lower smog rates. On Monday, the motorists with evennumbered license plates numbers would be ordered to leave their cars at home, or they would suffer a fine. Same rule would occur on Tuesday, except motorists with oddnumbered license plates were targeted with fines. Congestion, or traffic, was reduced by 60% after five days of intense smog. Diesel fuel played a huge part in this pollution, having the fact that 67% of vehicles in France are of Diesel fuel. The impact of the clearing of smog, resided in banning the Tuesday rule of odd license plates.
Could you imagine a day without seeing a single car being used? This phenomenon occurs once a year in Bogota, Colombia. With the exception of buses and taxis being used, cars are to be left unattended for an entire day. Having a carfree day just once a year can even reduce the pollution slightly. The day without cars is part of a campaign that originated in Bogota in the mid 1990s. This campaign has renewed and constructed numerous bicycle paths and sidewalks all over the city. Parks and sports centers have also sprung from this campaign. Devoting your time to a carfree lifestyle has it's hassles, but in hindsight, it has it's benefits.
To conclude, living a carfree lifestyle does not seem like a possibility in this day and age, however managing the use of cars and pollution is something every country should take time investing in. Think about how much of an impact it would be if everywhere worldwide would take part in airpollution reduction. Mobile transportation is lifestyle in a sense, and being dependent on cars or other means of transportation can impact the health of the Earth and even ourselves.
Essay 2 :
"America's love affair with it's vehicles seems to be cooling" says Elisabeth rosenthal. To understand rosenthal's perspective, it is easier to suggest that America's car usage is decreasing slowly. This isn't necessarily bad in the sense that it has certain positive effects. The advantages of limiting car usage includes an increase in security and health, along with a decrease in pollution and dependence.
Firstly, when car usage is limited security and health is more likely to be guaranteed. The feeling of being secure is highly important to individuals everywhere. For example, many people in colombia used public transportation during a car free day "leaving the streets of this capital city ", according to Andrew Selsky, "eerily devoid of traffic jams". The complications that stem from traffic jams end with a feeling of confidence. The plan to get from point A to B was more simple just a second ago. This complication in your personal plans leads you to become stressed as a feeling of doubt overcomes all thoughts. If car usage was limited, there would be a control on how much traffic accumulates thus minimizing chance of stress. As Heidrun Walter states "when i had a car i was always tense. I'm much happier this way". not only does car usage minimize conditions detrimental to health, it also enlarges your capacity for exercise. The main purpose of the car is to get someone from one place to another. when an important job takes over your personal life, it becomes difficult to do things most enjoyed in life. limits on car usage forces you to stay in shape. According to Andrew Selsky "parks and sports centers also have bloomed throughout the city". Less cars means healthier and natural situations. With parks and sport centers becoming more efficient, it becomes easier to find a more physically active population. Overall, less usage on cars minimizes stress and increases health.
Secondly, limting car usage becomes beneficial to the environment. Now a days people have become annoyed with others who care so passionately about the environment. If you look behind their constant cries for action, there are solid facts. Yespollution is bad for the environment. Yes a bad envorment means unhealthy living. Yes cars are one of the main contributors to pollution in the environment. A pattern of less car usage, as Elisabeth Rosenthal states "will have beneficial implications for carbon emissions and the environment". The less use of cars, the less pollution in the environment. One must observe limiting car usage as an opportunity to create a cleaner world and better future. The effects of pollution in the environment is completley dangerous and we, the car users, are to blame.
Additionally, it would lower the dependence on cars. Many people today find that their car is so useful. While it has many features and is a form of transportation, many do not figure what they would do if they did not have such a possesion. The development of people and their interaction with technology has left a wide gap between historic, natural ways and what is thought of as modern society. Being dependent is not always good for individuals. As david goldberg says "all our development since world war II has been centered on the car, and that will have to change". Many people could disagree and wonder why it is necessary to change our ways especially if we are so highly devloped. If being developed means being dependent on a harmful machine, then it could not be effective devlopment. According to Elisabeth Rosenthal "cashstrapped americans could not afford new cars, and the unemployed were't going to work anyway". Many people can't have the precious luxury of private transportation in the first place. Those who have had it have become distant to a more natural society. Peope have become so use to having cars that they have become oblivious to the significant effects. With limits on car usage , these effcts could be controlled.
To conclude, the advantages of limiting car usage is an increase in health, along with a decrease in pollution, and less dependence on cars. limiting car usage is a positive way to enfore an organized and clean environment, and ensure health and security of those who live in it. This is one reason America can be reffered to as a succesful country. It is not that America has decreased use of vehicles, but the fact that they have done what is best for majority.
Looking at some of these essays, we can see there are a range of formats these essays take. Some utilize quotes, some describe statistics, most have multiple paragraphs, although the actual paragraph number vary.
df = train_essays[train_essays['generated'] == 0].copy()
df['Word Count'] = df['text'].apply(lambda x: len(x.split(sep=' ')))
fig, ax = plt.subplots()
ax.hist(df['Word Count'], bins=50)
ax.set_ylabel('Essays')
ax.set_xlabel('Word Count')
ax.set_title('Histogram of Text Word Length for Non-AI Generated Essays')
ax.vlines(df['Word Count'].quantile(0.5), 0, 120, color='black')
ax.vlines(df['Word Count'].quantile(0.25), 0, 120, color='black', linestyle='dotted')
ax.vlines(df['Word Count'].quantile(0.75), 0, 120, color='black', linestyle='dotted')
fig.show()

print('Median: ', df['Word Count'].quantile(0.5))
print('Q1: ', df['Word Count'].quantile(0.25))
print('Q3: ', df['Word Count'].quantile(0.75))
Median: 521.0
Q1: 444.5
Q3: 635.0
The real essays seem to vary in length. On average, the essays are around 500 words, but can be as long as 1,400 words or as short as a less than 200 words.
We can now take a look at the three generated essays.
take = 3
for i in range(take):
print('Essay ',i,':')
print(train_essays[train_essays['generated'] == 1].reset_index().loc[i]['text'])
print('')
Essay 0 :
This essay will analyze, discuss and prove one reason in favor of keeping the Electoral College in the United States for its presidential elections. One of the reasons to keep the electoral college is that it is better for smaller, more rural states to have more influence as opposed to larger metropolitan areas that have large populations. The electors from these states are granted two votes each. Those from larger, more populated areas are granted just one vote each. Smaller states tend to hold significant power because their two votes for president and vice president add up more than the votes of larger states that have many electors. This is because of the split of the electoral votes. Some argue that electors are not bound to vote for the candidate who won the most votes nationally. They do not have to vote for their own state's nominee unless their state has a winner take all system. However, there are states that have adopted laws that force their electors to vote for their state's candidate. It seems that, no matter how, electors are not bound to vote for the candidate who won the most nationally. This is not always the case because of state legislatures who can overrule the electors and vote for the alternative candidate their citizens have selected for them, even if the voter lives in a state without a winner take all system.
Essay 1 :
I strongly believe that the Electoral College should remain the way it is or, better yet, that we should elect the president by popular vote. This is due to the fact that the Electoral College does not accurately reflect the will of the people. For example, in the 2016 presidential election, an estimated two million more people voted for Hillary Clinton than for Donald Trump however, Trump won the Electoral College vote, 304 to 232. This means that a candidate can win a majority of the Electoral College voters while losing the popular vote! Furthermore, voting for President should be an individual citizen decision, not a state decision. The Electoral College works by awarding all of a state's electoral votes to the winner of the majority of votes in the state. This means that a candidate can win the majority of votes in a state and still not receive any of that states electoral votes. This goes against the concept of onepersononevote, since a candidate can win the majority of votes in a state and still not win any electoral votes. By eliminating the Electoral College and electing the president by popular vote, the votes of every individual will be counted, and the candidate who wins the most votes nationally will win the election. In conclusion, the Electoral College does not reflect the will of the people and votes in state are not equally weighted. It is time to elect the president by popular vote and to finally give the votes of individual citizens the weight they deserve.
Essay 2 :
Limiting car use causes pollution, increases costs to users regardless of where services or services are offered. Furthermore, over use of the gas results in increased environmental degradation, harming our resources while damaging our environment.
When consumers pay a larger amount before gasoline is refined then there are higher costs of running the engine than otherwise. There are fewer places where the gas can be purchased locally causing more problems. Car trips will usually have higher tolls which results in lost wages for the transportation worker, who goes to an unnecessary location for work and then returns home and gets to pay back his transportation back costs. The car accident rate amongst children also has increased. Car pollution can become airborne easily, contaminating children's health. Also children tend to be more careless and more often in accidents simply because of being pushed out of their cars onto the road. All of this can be done to better an already polluted Earth that is becoming increasingly damaged at a much faster rate. Limiting our vehicle use helps our citizens with a reduced budget. It also reduces pollution for local areas. Furthermore, it improves public health and makes city dwellers a wealthier society.
Limiting our own usage by adopting public transportation, walking, biking, and public transport actually would be beneficial for the citizens and planet. I think its very healthy but very little others show similar sentiment mostly environmental activists who want a more environmentally clean place so it often is still looked down upon it still will bring about a very drastic price eventually but there will never be carbon credit trading or an oil recycling scheme unless people want it too. Limiting car use is good for the city.
df = train_essays[train_essays['generated'] == 1].copy()
df['Word Count'] = df['text'].apply(lambda x: len(x.split(sep=' ')))
fig, ax = plt.subplots()
ax.hist(df['Word Count'], bins=50)
ax.set_ylabel('Essays')
ax.set_xlabel('Word Count')
ax.set_title('Histogram of Text Word Length for AI Generated Essays')
ax.vlines(df['Word Count'].quantile(0.5), 0, 5, color='black')
ax.vlines(df['Word Count'].quantile(0.25), 0, 5, color='black', linestyle='dotted')
ax.vlines(df['Word Count'].quantile(0.75), 0, 5, color='black', linestyle='dotted')
fig.show()

print('Median: ', df['Word Count'].quantile(0.5))
print('Q1: ', df['Word Count'].quantile(0.25))
print('Q3: ', df['Word Count'].quantile(0.75))
Median: 258.0
Q1: 246.5
Q3: 272.5
Compared to the real essays, the AI generated essays are much shorter and do not seem to use direct quotations or utilize multiple paragraphs. However, the above conclusions and statistics may not be the cases if we add in additional known AI generated essays.
Data Generation for AI Generation Esssays
Due to the imbalance of AI and Non-AI generated essays, we can import some additional AI generated essays from the LLM: Mistral-7B Instruct texts, which includes essays for prompts ‘Car-free cities’ and ‘Does the electoral college work,’ both of which match the original prompt minus the provided texts.
Data Citation:
Ellis, C. M. (2023, November 29). LLM: Mistral-7B instruct texts. LLM: Mistral-7B Instruct texts. https://www.kaggle.com/datasets/carlmcbrideellis/llm-mistral-7b-instruct-texts?select=Mistral7B_CME_v7.csv
add_ai_essays = pd.read_csv('/kaggle/input/llm-mistral-7b-instruct-texts/Mistral7B_CME_v7.csv')
add_ai_essays[['prompt_name','prompt_id']].groupby('prompt_name', as_index=False).max('prompt_id')
| prompt_name | prompt_id | |
|---|---|---|
| 0 | A Cowboy Who Rode the Waves | 4 |
| 1 | Car-free cities | 2 |
| 2 | Does the electoral college work? | 12 |
| 3 | Driverless cars | 11 |
| 4 | Exploring Venus | 6 |
| 5 | Facial action coding system | 7 |
| 6 | The Face on Mars | 8 |
add_ai_essays = add_ai_essays[(add_ai_essays['prompt_id'] == 2) | (add_ai_essays['prompt_id'] == 12)]
print('New Prompt 0 (Cars):', len(add_ai_essays[add_ai_essays['prompt_id']==2]))
print('New Prompt 1 (Electoral College):', len(add_ai_essays[add_ai_essays['prompt_id']==12]))
New Prompt 0 (Cars): 700
New Prompt 1 (Electoral College): 700
Adding these AI generated essays will functionally double our training dataset!
train_essays_full = train_essays.copy()
add_ai_essays['id'] = None
add_ai_essays = add_ai_essays.drop(columns={'prompt_name'})
add_ai_essays['prompt_id'] = add_ai_essays['prompt_id'].map({2: 0, 12: 1})
train_essays_full = pd.concat([train_essays_full,add_ai_essays])
train_essays_full = train_essays_full.reset_index().drop(columns={'index'})
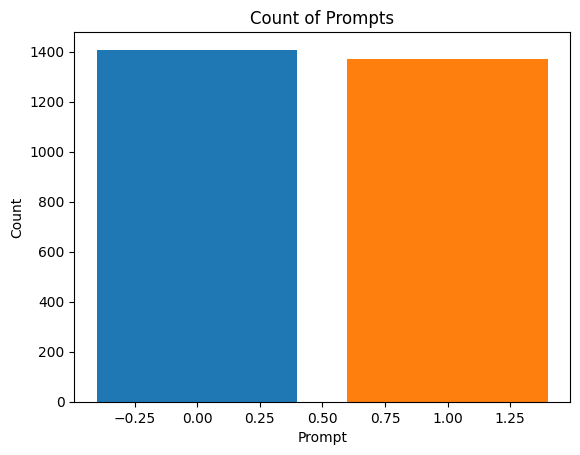
df = pd.DataFrame(train_essays_full['prompt_id'].value_counts()).reset_index()
fig, ax = plt.subplots()
ax.bar(df['prompt_id'],df['count'], color=['tab:blue','tab:orange'])
ax.set_ylabel('Count')
ax.set_xlabel('Prompt')
ax.set_title('Count of Prompts')
plt.show()
df = pd.DataFrame(train_essays_full['generated'].value_counts()).reset_index()
fig, ax = plt.subplots()
ax.bar(df['generated'],df['count'], color=['tab:blue','tab:orange'])
ax.set_ylabel('Count')
ax.set_xlabel('AI Generated')
ax.set_title('Count of Generated Essays')
plt.show()

We can see from the plots above that the balance of essays for each prompt remains balanced, but the overall number of AI generated essays is now at the same level of the non-AI generated essays.
df = train_essays_full[train_essays_full['generated'] == 1].copy()
df['Word Count'] = df['text'].apply(lambda x: len(x.split(sep=' ')))
fig, ax = plt.subplots()
ax.hist(df['Word Count'], bins=50)
ax.set_ylabel('Essays')
ax.set_xlabel('Word Count')
ax.set_title('Histogram of Text Word Length for AI Generated Essays')
ax.vlines(df['Word Count'].quantile(0.5), 0, 140, color='black')
ax.vlines(df['Word Count'].quantile(0.25), 0, 140, color='black', linestyle='dotted')
ax.vlines(df['Word Count'].quantile(0.75), 0, 140, color='black', linestyle='dotted')
fig.show()

print('Median: ', df['Word Count'].quantile(0.5))
print('Q1: ', df['Word Count'].quantile(0.25))
print('Q3: ', df['Word Count'].quantile(0.75))
Median: 417.0
Q1: 374.0
Q3: 467.0
Looking at the word count plots and statistics, overall, the AI generated essays are still shorter than non-AI generated essays.
Data Cleaning and Text Processing
Like other Natural Language Processing projects, we must first clean the text before model ingestion. This project in particular must clean the data before ingestion to ensure the first N words chosen for the model are important. Here is the raw text before cleaning:
print(train_essays_full.loc[1:2]['text'].values)
['Transportation is a large necessity in most countries worldwide. With no doubt, cars, buses, and other means of transportation make going from place to place easier and faster. However there\'s always a negative pollution. Although mobile transportation are a huge part of daily lives, we are endangering the Earth with harmful greenhouse gases, which could be suppressed.\n\nA small suburb community in Germany called Vauban, has started a "carfree" lifestyle. In this city, markets and stores are placed nearby homes, instead of being located by farend highways. Although Vauban is not completely carfree, 70% of Vauban families do not own cars Even a large 57% of families stated to have sold their cars to move to Vauban. Some families have even said to be less stressed depending on car transportation. Cars are responsible for about 12% of greenhouse gases, and can even be up to 50% in some carintensive areas in the United States.\n\nAnother insight to reduced car zones brings Paris\' incident with smog. Paris\' officials created a system that would in fact lower smog rates. On Monday, the motorists with evennumbered license plates numbers would be ordered to leave their cars at home, or they would suffer a fine. Same rule would occur on Tuesday, except motorists with oddnumbered license plates were targeted with fines. Congestion, or traffic, was reduced by 60% after five days of intense smog. Diesel fuel played a huge part in this pollution, having the fact that 67% of vehicles in France are of Diesel fuel. The impact of the clearing of smog, resided in banning the Tuesday rule of odd license plates.\n\nCould you imagine a day without seeing a single car being used? This phenomenon occurs once a year in Bogota, Colombia. With the exception of buses and taxis being used, cars are to be left unattended for an entire day. Having a carfree day just once a year can even reduce the pollution slightly. The day without cars is part of a campaign that originated in Bogota in the mid 1990s. This campaign has renewed and constructed numerous bicycle paths and sidewalks all over the city. Parks and sports centers have also sprung from this campaign. Devoting your time to a carfree lifestyle has it\'s hassles, but in hindsight, it has it\'s benefits.\n\nTo conclude, living a carfree lifestyle does not seem like a possibility in this day and age, however managing the use of cars and pollution is something every country should take time investing in. Think about how much of an impact it would be if everywhere worldwide would take part in airpollution reduction. Mobile transportation is lifestyle in a sense, and being dependent on cars or other means of transportation can impact the health of the Earth and even ourselves.'
'"America\'s love affair with it\'s vehicles seems to be cooling" says Elisabeth rosenthal. To understand rosenthal\'s perspective, it is easier to suggest that America\'s car usage is decreasing slowly. This isn\'t necessarily bad in the sense that it has certain positive effects. The advantages of limiting car usage includes an increase in security and health, along with a decrease in pollution and dependence.\n\nFirstly, when car usage is limited security and health is more likely to be guaranteed. The feeling of being secure is highly important to individuals everywhere. For example, many people in colombia used public transportation during a car free day "leaving the streets of this capital city ", according to Andrew Selsky, "eerily devoid of traffic jams". The complications that stem from traffic jams end with a feeling of confidence. The plan to get from point A to B was more simple just a second ago. This complication in your personal plans leads you to become stressed as a feeling of doubt overcomes all thoughts. If car usage was limited, there would be a control on how much traffic accumulates thus minimizing chance of stress. As Heidrun Walter states "when i had a car i was always tense. I\'m much happier this way". not only does car usage minimize conditions detrimental to health, it also enlarges your capacity for exercise. The main purpose of the car is to get someone from one place to another. when an important job takes over your personal life, it becomes difficult to do things most enjoyed in life. limits on car usage forces you to stay in shape. According to Andrew Selsky "parks and sports centers also have bloomed throughout the city". Less cars means healthier and natural situations. With parks and sport centers becoming more efficient, it becomes easier to find a more physically active population. Overall, less usage on cars minimizes stress and increases health.\n\nSecondly, limting car usage becomes beneficial to the environment. Now a days people have become annoyed with others who care so passionately about the environment. If you look behind their constant cries for action, there are solid facts. Yespollution is bad for the environment. Yes a bad envorment means unhealthy living. Yes cars are one of the main contributors to pollution in the environment. A pattern of less car usage, as Elisabeth Rosenthal states "will have beneficial implications for carbon emissions and the environment". The less use of cars, the less pollution in the environment. One must observe limiting car usage as an opportunity to create a cleaner world and better future. The effects of pollution in the environment is completley dangerous and we, the car users, are to blame.\n\nAdditionally, it would lower the dependence on cars. Many people today find that their car is so useful. While it has many features and is a form of transportation, many do not figure what they would do if they did not have such a possesion. The development of people and their interaction with technology has left a wide gap between historic, natural ways and what is thought of as modern society. Being dependent is not always good for individuals. As david goldberg says "all our development since world war II has been centered on the car, and that will have to change". Many people could disagree and wonder why it is necessary to change our ways especially if we are so highly devloped. If being developed means being dependent on a harmful machine, then it could not be effective devlopment. According to Elisabeth Rosenthal "cashstrapped americans could not afford new cars, and the unemployed were\'t going to work anyway". Many people can\'t have the precious luxury of private transportation in the first place. Those who have had it have become distant to a more natural society. Peope have become so use to having cars that they have become oblivious to the significant effects. With limits on car usage , these effcts could be controlled.\n\nTo conclude, the advantages of limiting car usage is an increase in health, along with a decrease in pollution, and less dependence on cars. limiting car usage is a positive way to enfore an organized and clean environment, and ensure health and security of those who live in it. This is one reason America can be reffered to as a succesful country. It is not that America has decreased use of vehicles, but the fact that they have done what is best for majority.']
We will now create a function of multiple functions that will remove text features that do not make sense to be parsed, including apostrophes, extra spaces, punctuation, and stop words within the nlp model.
def remove_newline(text):
return re.sub('\\n', '', text)
def remove_ss(text):
return re.sub('\\\'s', '', text)
def remove_ap(text):
return re.sub('\\\'', '', text)
def remove_period(text):
text = re.sub('\. ', ' ', text)
return re.sub('\.', ' ', text)
def remove_char(text):
return re.sub('[^a-zA-Z\d\s:]', '', text)
def remove_words(text):
doc = nlp(text)
n_text = [word.text for word in doc if (word not in nlp.Defaults.stop_words)] #word.text forces back to string
return ' '.join(n_text) #forces back to full text
def clean_text(text):
text = remove_newline(text)
text = remove_ss(text)
text = remove_ap(text)
text = remove_period(text)
text = remove_char(text)
text = remove_words(text)
parts = text.split()[:250]
return ' '.join(parts)
train_essays_full['text_clean'] = train_essays_full['text'].apply(clean_text)
print(train_essays_full.loc[1:2]['text_clean'].values)
['Transportation is a large necessity in most countries worldwide With no doubt cars buses and other means of transportation make going from place to place easier and faster However there always a negative pollution Although mobile transportation are a huge part of daily lives we are endangering the Earth with harmful greenhouse gases which could be suppressed A small suburb community in Germany called Vauban has started a carfree lifestyle In this city markets and stores are placed nearby homes instead of being located by farend highways Although Vauban is not completely carfree 70 of Vauban families do not own cars Even a large 57 of families stated to have sold their cars to move to Vauban Some families have even said to be less stressed depending on car transportation Cars are responsible for about 12 of greenhouse gases and can even be up to 50 in some carintensive areas in the United States Another insight to reduced car zones brings Paris incident with smog Paris officials created a system that would in fact lower smog rates On Monday the motorists with evennumbered license plates numbers would be ordered to leave their cars at home or they would suffer a fine Same rule would occur on Tuesday except motorists with oddnumbered license plates were targeted with fines Congestion or traffic was reduced by 60 after five days of intense smog Diesel fuel played a huge part in this pollution having the fact that 67 of vehicles in France are of'
'America love affair with it vehicles seems to be cooling says Elisabeth rosenthal To understand rosenthal perspective it is easier to suggest that America car usage is decreasing slowly This is nt necessarily bad in the sense that it has certain positive effects The advantages of limiting car usage includes an increase in security and health along with a decrease in pollution and dependence Firstly when car usage is limited security and health is more likely to be guaranteed The feeling of being secure is highly important to individuals everywhere For example many people in colombia used public transportation during a car free day leaving the streets of this capital city according to Andrew Selsky eerily devoid of traffic jams The complications that stem from traffic jams end with a feeling of confidence The plan to get from point A to B was more simple just a second ago This complication in your personal plans leads you to become stressed as a feeling of doubt overcomes all thoughts If car usage was limited there would be a control on how much traffic accumulates thus minimizing chance of stress As Heidrun Walter states when i had a car i was always tense I m much happier this way not only does car usage minimize conditions detrimental to health it also enlarges your capacity for exercise The main purpose of the car is to get someone from one place to another when an important job takes over your personal life it becomes']
The clean text now has no ‘'s, no single apostrophes, or punctuation characters. The text is now at most 250 cleaned words long.
Train Test Split
We will now split the dataset into training and testing sets. We will split the data into 80% Training and 20% Testing.
X_train, X_test = train_test_split(train_essays_full[['generated','text_clean']], test_size=0.2, stratify = train_essays_full['generated'], random_state =101)
print('Train Length:', len(X_train),'\t Percent AI Generated: %.2f' %(len(X_train[X_train['generated']==1])/len(X_train)*100),'%')
print('Test Length:', len(X_test),'\t Percent AI Generated: %.2f' %(len(X_train[X_train['generated']==1])/len(X_train)*100),'%')
print('Percent Split: %.2f' %(len(X_test)/(len(X_train)+len(X_test))), '%')
# Force to Tensor Datasets
tensor_train_text = tf.convert_to_tensor(X_train['text_clean'].values)
X_train_t = tf.data.Dataset.from_tensor_slices((tensor_train_text, X_train['generated']))
tensor_test_text = tf.convert_to_tensor(X_test['text_clean'].values)
X_test_t = tf.data.Dataset.from_tensor_slices((tensor_test_text, X_test['generated']))
BATCH_SIZE = 64
train_dataset = X_train_t.shuffle(len(X_train_t), seed=101).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
test_dataset = X_test_t.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
Train Length: 2222 Percent AI Generated: 50.50 %
Test Length: 556 Percent AI Generated: 50.50 %
Percent Split: 0.20 %
Text Vectorization
We can use this tutorial to leverage TensorFlow functions to further clean and vectorize text. We will set the maximum length to be 250, which will just take the first 250 words in the essay.
max_features = 10000
vectorize_layer = layers.TextVectorization(
max_tokens=max_features,
output_mode='tf_idf',
pad_to_max_tokens=True
)
train_text = train_dataset.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
Modeling
We can now build the model. We will utilize TensorFlow to vectorize text within the Neural Network. We can start with a bidirectional sequential neural network using our custom text vectorization.
def plot_func(history):
history_dict = history.history
history_dict.keys()
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
first_model = tf.keras.Sequential([
vectorize_layer,
layers.Embedding(max_features,128),
layers.Bidirectional(layers.LSTM(32)),
layers.Dense(128, activation='relu'),
layers.Dropout(0.7),
layers.Dense(64, activation='relu'),
layers.Dropout(0.5),
layers.Dense(16, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
first_model.compile(loss=tf.keras.losses.BinaryCrossentropy(), metrics=['accuracy'], optimizer='adam')
first_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVe (None, 10000) 1
ctorization)
embedding (Embedding) (None, 10000, 128) 1280000
bidirectional (Bidirection (None, 64) 41216
al)
dense (Dense) (None, 128) 8320
dropout (Dropout) (None, 128) 0
dense_1 (Dense) (None, 64) 8256
dropout_1 (Dropout) (None, 64) 0
dense_2 (Dense) (None, 16) 1040
dense_3 (Dense) (None, 1) 17
=================================================================
Total params: 1338850 (5.11 MB)
Trainable params: 1338849 (5.11 MB)
Non-trainable params: 1 (8.00 Byte)
_________________________________________________________________
history = first_model.fit(x=train_dataset, validation_data=test_dataset, epochs=10)
Epoch 1/10
35/35 [==============================] - 34s 603ms/step - loss: 0.6919 - accuracy: 0.5131 - val_loss: 0.6904 - val_accuracy: 0.4946
Epoch 2/10
35/35 [==============================] - 18s 521ms/step - loss: 0.6885 - accuracy: 0.5419 - val_loss: 0.6651 - val_accuracy: 0.6655
Epoch 3/10
35/35 [==============================] - 18s 525ms/step - loss: 0.5872 - accuracy: 0.7147 - val_loss: 0.5155 - val_accuracy: 0.7626
Epoch 4/10
35/35 [==============================] - 18s 529ms/step - loss: 0.4594 - accuracy: 0.8083 - val_loss: 0.3930 - val_accuracy: 0.8309
Epoch 5/10
35/35 [==============================] - 18s 518ms/step - loss: 0.3927 - accuracy: 0.8492 - val_loss: 0.4548 - val_accuracy: 0.7788
Epoch 6/10
35/35 [==============================] - 18s 519ms/step - loss: 0.3815 - accuracy: 0.8461 - val_loss: 0.3756 - val_accuracy: 0.8417
Epoch 7/10
35/35 [==============================] - 18s 523ms/step - loss: 0.3504 - accuracy: 0.8650 - val_loss: 0.3753 - val_accuracy: 0.8471
Epoch 8/10
35/35 [==============================] - 18s 524ms/step - loss: 0.3554 - accuracy: 0.8677 - val_loss: 0.3684 - val_accuracy: 0.8489
Epoch 9/10
35/35 [==============================] - 18s 517ms/step - loss: 0.3533 - accuracy: 0.8695 - val_loss: 0.3839 - val_accuracy: 0.8327
Epoch 10/10
35/35 [==============================] - 18s 519ms/step - loss: 0.3348 - accuracy: 0.8731 - val_loss: 0.4087 - val_accuracy: 0.8219
plot_func(history)


It looks like the model performed the best at 9 epochs. We did not save any history, so we will visualize the results at 10 epochs.
first_pred = first_model.predict(test_dataset)
9/9 [==============================] - 3s 210ms/step
def cm_visual(pred, test_dataset):
test_y = []
for i in list(test_dataset):
for j in i[1]:
test_y.append(int(j))
# turning into 1/0 predictions
pred[pred >= 0.5] = 1
pred[pred < 0.5] = 0
pred = pred.reshape(1,-1)[0]
print('Length:', len(test_y))
cm = confusion_matrix(test_y, pred)
cmd = ConfusionMatrixDisplay(cm)
cmd.plot()
print('Accuracy: %.2f' %(accuracy_score(test_y, pred)))
print('F1: %.2f' %(f1_score(test_y, pred)))
print('Precision: %.2f' %(precision_score(test_y, pred)))
print('Recall: %.2f' %(recall_score(test_y, pred)))
cm_visual(first_pred, test_dataset)
Length: 556
Accuracy: 0.82
F1: 0.81
Precision: 0.87
Recall: 0.77

Looking at the confusion matrix, the model did worse in instances where the essay was AI generated than when (false negative) than when the essay was not AI generated (false positives). Neither ‘false’ classification is worse than another; on the one hand, accusing a non-AI generated paper as AI generated is not great and might cause frustration from the student who wrote the paper. On the other hand, not catching AI generated papers is a disservice to the students who wrote a paper.
For our second model, we will use BERT, a pre-trained bi-directional large language model, to encode the text.
preprocessor = hub.KerasLayer(
"https://kaggle.com/models/tensorflow/bert/frameworks/TensorFlow2/variations/en-uncased-preprocess/versions/3")
encoder = hub.KerasLayer(
"https://www.kaggle.com/models/tensorflow/bert/frameworks/TensorFlow2/variations/bert-en-uncased-l-4-h-128-a-2/versions/2",
trainable=True)
text_input = layers.Input(shape=(), dtype=tf.string)
encoder_inputs = preprocessor(text_input)
outputs = encoder(encoder_inputs)
pooled_output = outputs['pooled_output']
sequence_output = outputs['sequence_output']
dense1 = layers.Dense(128, activation='relu')(pooled_output)
dropout1 = layers.Dropout(0.7, name='dropout1')(pooled_output)
dense2 = layers.Dense(64, activation='relu')(dropout1)
dropout = layers.Dropout(0.5, name='dropout2')(dense2)
dense3 = layers.Dense(16, activation='relu')(dropout)
dropout = layers.Dropout(0.5, name='dropout3')(dropout)
dense_out = layers.Dense(1, activation='sigmoid', name='output')(dropout)
second_model = tf.keras.Model(inputs=text_input, outputs=dense_out)
second_model.compile(loss=tf.keras.losses.BinaryCrossentropy(), metrics=['accuracy'], optimizer='adam')
second_model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None,)] 0 []
keras_layer (KerasLayer) {'input_word_ids': (None, 0 ['input_1[0][0]']
128),
'input_mask': (None, 128)
, 'input_type_ids': (None,
128)}
keras_layer_1 (KerasLayer) {'default': (None, 128), 4782465 ['keras_layer[0][0]',
'encoder_outputs': [(None 'keras_layer[0][1]',
, 128, 128), 'keras_layer[0][2]']
(None, 128, 128),
(None, 128, 128),
(None, 128, 128)],
'pooled_output': (None, 1
28),
'sequence_output': (None,
128, 128)}
dropout1 (Dropout) (None, 128) 0 ['keras_layer_1[0][5]']
dense_5 (Dense) (None, 64) 8256 ['dropout1[0][0]']
dropout2 (Dropout) (None, 64) 0 ['dense_5[0][0]']
dropout3 (Dropout) (None, 64) 0 ['dropout2[0][0]']
output (Dense) (None, 1) 65 ['dropout3[0][0]']
==================================================================================================
Total params: 4790786 (18.28 MB)
Trainable params: 4790785 (18.28 MB)
Non-trainable params: 1 (1.00 Byte)
__________________________________________________________________________________________________
history = second_model.fit(x=train_dataset, validation_data=test_dataset, epochs=10)
Epoch 1/10
35/35 [==============================] - 33s 508ms/step - loss: 0.7735 - accuracy: 0.5914 - val_loss: 0.1065 - val_accuracy: 0.9766
Epoch 2/10
35/35 [==============================] - 17s 484ms/step - loss: 0.1944 - accuracy: 0.9374 - val_loss: 0.0869 - val_accuracy: 0.9856
Epoch 3/10
35/35 [==============================] - 16s 457ms/step - loss: 0.1384 - accuracy: 0.9680 - val_loss: 0.1080 - val_accuracy: 0.9784
Epoch 4/10
35/35 [==============================] - 14s 395ms/step - loss: 0.0859 - accuracy: 0.9802 - val_loss: 0.1010 - val_accuracy: 0.9766
Epoch 5/10
35/35 [==============================] - 15s 428ms/step - loss: 0.0535 - accuracy: 0.9910 - val_loss: 0.0421 - val_accuracy: 0.9856
Epoch 6/10
35/35 [==============================] - 15s 418ms/step - loss: 0.0239 - accuracy: 0.9964 - val_loss: 0.0778 - val_accuracy: 0.9892
Epoch 7/10
35/35 [==============================] - 14s 410ms/step - loss: 0.0498 - accuracy: 0.9896 - val_loss: 0.0571 - val_accuracy: 0.9820
Epoch 8/10
35/35 [==============================] - 14s 412ms/step - loss: 0.0393 - accuracy: 0.9874 - val_loss: 0.0734 - val_accuracy: 0.9874
Epoch 9/10
35/35 [==============================] - 12s 349ms/step - loss: 0.0279 - accuracy: 0.9941 - val_loss: 0.0470 - val_accuracy: 0.9910
Epoch 10/10
35/35 [==============================] - 12s 355ms/step - loss: 0.0489 - accuracy: 0.9878 - val_loss: 0.0680 - val_accuracy: 0.9712
plot_func(history)


Wow! Using BERT is a large improvement from using the untrained NLP before! The second model is also much faster to train than the first model, likely because the NLP model is already bi-directionally trained. We can now investigate the resulting confusion matrix.
second_pred = second_model.predict(test_dataset)
cm_visual(second_pred, test_dataset)
9/9 [==============================] - 2s 204ms/step
Length: 556
Accuracy: 0.97
F1: 0.97
Precision: 0.95
Recall: 0.99

Overall, it looks like the BERT model is performing much better than the first model. This model has more false positives (not an AI-generated model, but predicted as such) than false negatives (AI generated model, but predicted as non-AI generated).
Supervised Models
We can quickly train a few supervised models to compare performance. We will use the first deep learning model, which uses tf-idf to vectorize sentences.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import LinearSVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import RidgeClassifier, LogisticRegression, SGDClassifier
tfidf = TfidfVectorizer(max_features=10000, stop_words='english')
train_x2 = tfidf.fit_transform(X_train['text_clean'])
test_x2 = tfidf.transform(X_test['text_clean'])
train_y2 = X_train['generated'].values
test_y2 = X_test['generated'].values
svc_model = LinearSVC()
knn_model = KNeighborsClassifier()
sgd_model = SGDClassifier()
dt_model = DecisionTreeClassifier()
rf_model = RandomForestClassifier()
rg_model = RidgeClassifier()
lg_model = LogisticRegression()
svc_model.fit(train_x2,train_y2)
knn_model.fit(train_x2,train_y2)
sgd_model.fit(train_x2,train_y2)
dt_model.fit(train_x2,train_y2)
rf_model.fit(train_x2,train_y2)
rg_model.fit(train_x2,train_y2)
lg_model.fit(train_x2,train_y2)
svc_predict = svc_model.predict(test_x2)
knn_predict = knn_model.predict(test_x2)
sgd_predict = sgd_model.predict(test_x2)
dt_predict = dt_model.predict(test_x2)
rf_predict = rf_model.predict(test_x2)
rg_predict = rg_model.predict(test_x2)
lg_predict = lg_model.predict(test_x2)
print('SVC Accuracy: %.3f' %(accuracy_score(test_y2, svc_predict)))
print('KNN Accuracy: %.3f' %(accuracy_score(test_y2, knn_predict)))
print('SGD Accuracy: %.3f' %(accuracy_score(test_y2, sgd_predict)))
print('DT Accuracy: %.3f' %(accuracy_score(test_y2, dt_predict)))
print('RF Accuracy: %.3f' %(accuracy_score(test_y2, rf_predict)))
print('RG Accuracy: %.3f' %(accuracy_score(test_y2, rg_predict)))
print('LG Accuracy: %.3f' %(accuracy_score(test_y2, rg_predict)))
SVC Accuracy: 0.996
KNN Accuracy: 0.986
SGD Accuracy: 0.996
DT Accuracy: 0.971
RF Accuracy: 0.996
RG Accuracy: 0.996
LG Accuracy: 0.996
We can easily see that the supervised learning models did extremely well, and fit and predicted the results in much less time than the deep learning models.
Conclusions
Overall, this project was fairly successful. While the results cannot be tested on the hidden test_essays, most of the models performed very well. Out of the two models tested, the model using BERT performed much better than the model using tf-idf. The supervised models all performed very well, and much better than the deep learning tf-idf model.
This project was very interesting to complete. My skills in using TensorFlow and creating deep learning networks have improved. Being able to shift over to use a different compute resource more targeted to training deep learning models has been helpful and sped up the overall time needed to run the entire notebook and cut training times of neural networks by half. Further improvements could be made by taking a larger number of words per essay. Additionally, saving models based on the best metrics would help ensure the best model is being used.